VLLM之PagedAttention
VLLM主要的代码就是LLMEngine。
1.PagedAttention基础概念

传统的推理框架中,大部分框架都会预先预留好每个请求需要用到的gpu显存空间,包括对KVcache的分配,因为推理生成的序列长度大小是否发预先知道的,所以大部分会按照(batch_size,max_seq_len)这样的固定尺寸分配,然后如上图所示,实际分配了很多内存,但最终实际用到的却没有多少,造成大量显存浪费。这里分为预留碎片、内部碎片、外部碎片(reserved, internal fragmentation, and external fragmentation) 。
预留碎片:被预先分配,最终在decoding阶段被用上了,没有浪费,但造成资源占用,其它请求无法使用这片内存。
内部碎片:预先分配,且最后没有用上,造成显存浪费。
外部碎片:两个预分分配内存块之间的显存。
外部碎片出现的原因举个例子如下(分段存储的示例):
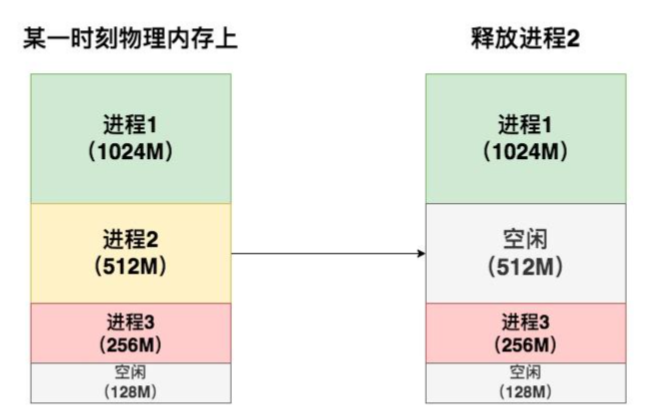
一开始按顺序分配,但是当某个进程结束,下一个进程分配进来时,没有512M,而空闲的那部分碎片又不足以分配一个进程,则造成了外部碎片。
所以为了解决这个问题,Vllm提出了PageAttention,PageAttention的灵感来源于操作系统的虚拟内存分页管理技术,如下图展现了单个request和多个request的执行流程。
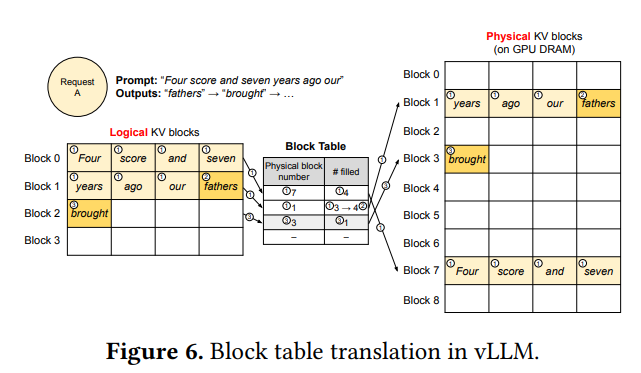
如第一个图,Request A 在逻辑KV内存块上认为自己是连续的,它感知不到屋里内存块上是如何存放的,一切都由中央调度器(Scheduler)来管理,主要是会维护一个Block Table,用来存放当前逻辑块指向的物理块号,以及filed(填充大小),根据填充大小即可知道是否填满,图中3->4即指,原本在prefill阶段,解码prompt的时候Block 1并没有填充满,而当解码出一个token后,会把这个块给填充满,当继续解码出下一个token时,又会开辟新的Block来存储。
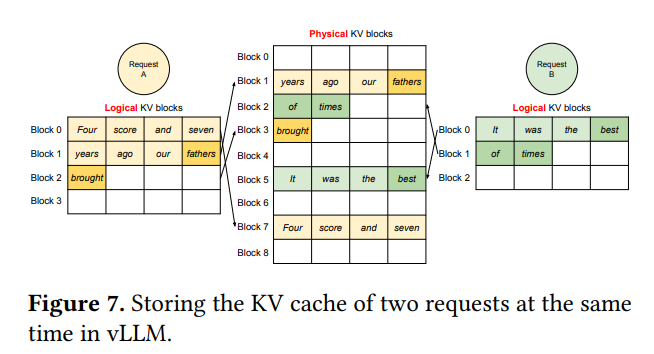
第二个图则展示了两个Request时的逻辑,两个Request都认为自己是独自享有显存,并在逻辑上是连续存储的,感知不到对方,也感知不到实际的内存存储位置,均由Block Table做映射。
2.PagedAttention在不同解码策略下的表现
PagedAttention对Parallel Sampling、Beam Search、Shared Prefix等解码方法做了适配如下:
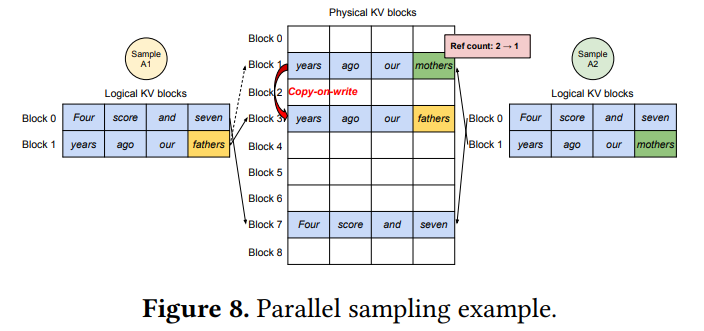
Parallel Sampling (并行采样),即给LLM发送一个请求对prompt续写,并给出多种回答。在这个场景中,把prompt复制多份拼接成一个batch的数据喂给模型,让它做推理,需要注意,这样prompt部分的KV cache会重复存储。
因此VLLM的处理方法是,只生成一份prompt的显存,并存储在实际的物理KV blocks中,此时Sample A1和Sample A2其实都指向Block1和Block7,�但block1没有填满;而当生成下一个词的时候,两个Sample的结果不一样了,因此这时候会做一个copy-on-write操作,把这一份prompt的数据进行复制到新的block上,即复制n-1份,n为要生成多份回答的数量。再分别填充这些Block。
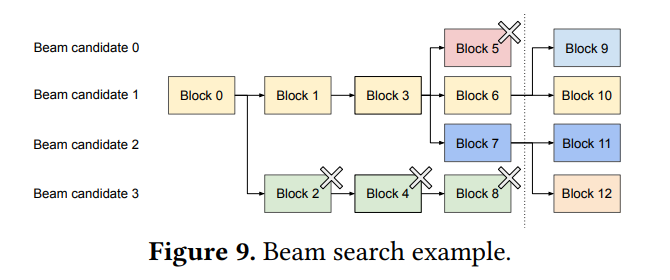
Beam Search 束搜索,即每次解码会从n个束的V个词表中,即个词中选取top_n个概率最大的词,再根据这n个词进行下一步解码。如图举例,虚线为解码的时刻,虚线左边此时解码的四条block分别对应block5、block6、block7、block8;根据此时四条路的token,进一步选择top-4个token,其中两个在block6中选出,另外两个在block7中选出,这时候,则会分别从block6对应的Beam 1延申出两条路,所以此时,Block5里面已经解码的内容是要被抛弃的,因此VLLM会清空Block5、Block8中的数据。
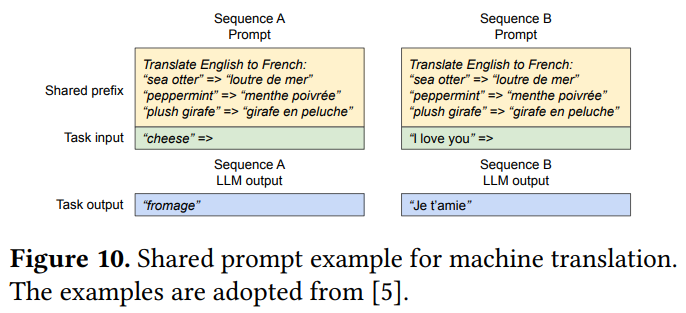
Shared Prefix则是�对于很多大模型来说,请求可能都会有相同的前置,比如System message,这些迁至信息没有必要重复存储KV cache,与Parallel Sampling的处理类似,只不过Parallel Sampling可能在初始解码的时候token一样,则可以继续共用block,直到分叉,而Shared Prefix仅仅是Prefix一致,Task input都是不一样的,所以只共享prefix部分的KV cache。
3.调度和抢占
当一顿请求来到VLLM服务器上时,采用一个调度原则来安排:
1.先来的请求先被服务(FCFS First Come First Serve)
2.如果有抢占,后来的请求先被抢占(preemption)
对于第二点,当因为gpu资源不足而被抢占的任务,VLLM需要暂停他们的执行,并释放与之相关的KV cache,等gpu资源充足时再执行。VLLM分别设计了Swapping(交换策略)和Recompute(冲计算策略)
(1)Swapping 对于抢占的请求,VLLM会把其 KV cache 从显存中全部释放掉,并把这些数据交换到cpu上,当gpu显存充足时,再重新加载回来。
(2) Recompute,当资源不足时,直接释放物理块,并将其重新放到等待队列中,当资源充足时再处理。
4.VLLM的分布式管理
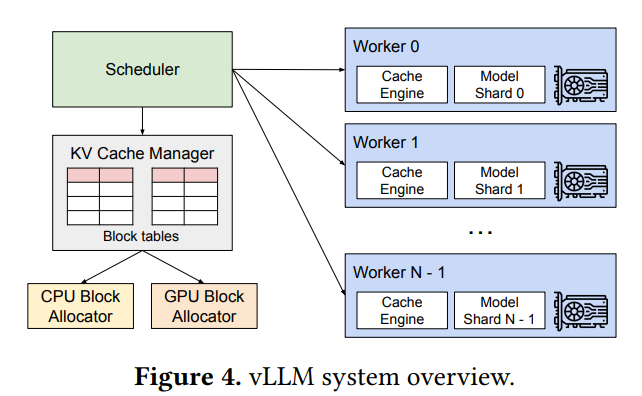
在分布式场景下,VLLM的整体运作流程如下:
- 首先会有一个中央调度器(Scheduler),负责计算和管理每张卡上的KV cache从逻辑块到物理块的映射表。
- 在做分布式计算时,Schecular会将映射表广播到各张卡上,每张卡上的Cache engine接收到相关信息后,负责管理各卡的block。