正确公式来自 IEEE 754 浮点数格式,指数是 以 2 为底数的偏移二进制指数(biased exponent),不是以 10 为底。
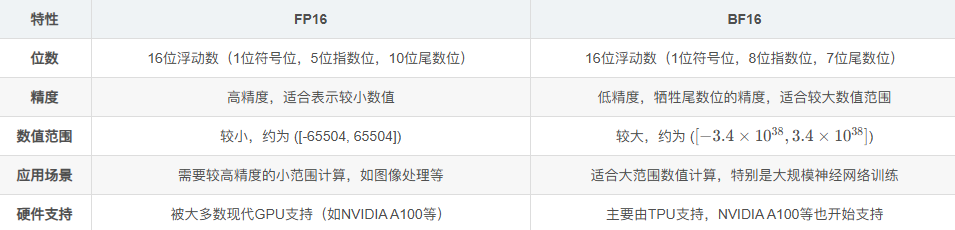
位数分布:
| 部分 | 位数 |
|---|
| 符号位 | 1 |
| 指数(Exponent) | 5 |
| 尾数(Mantissa) | 10 |
浮点数公式:
x=(−1)s⋅(1.m)2⋅2(e−bias)
其中
bias=2k−1−1=24−1=15
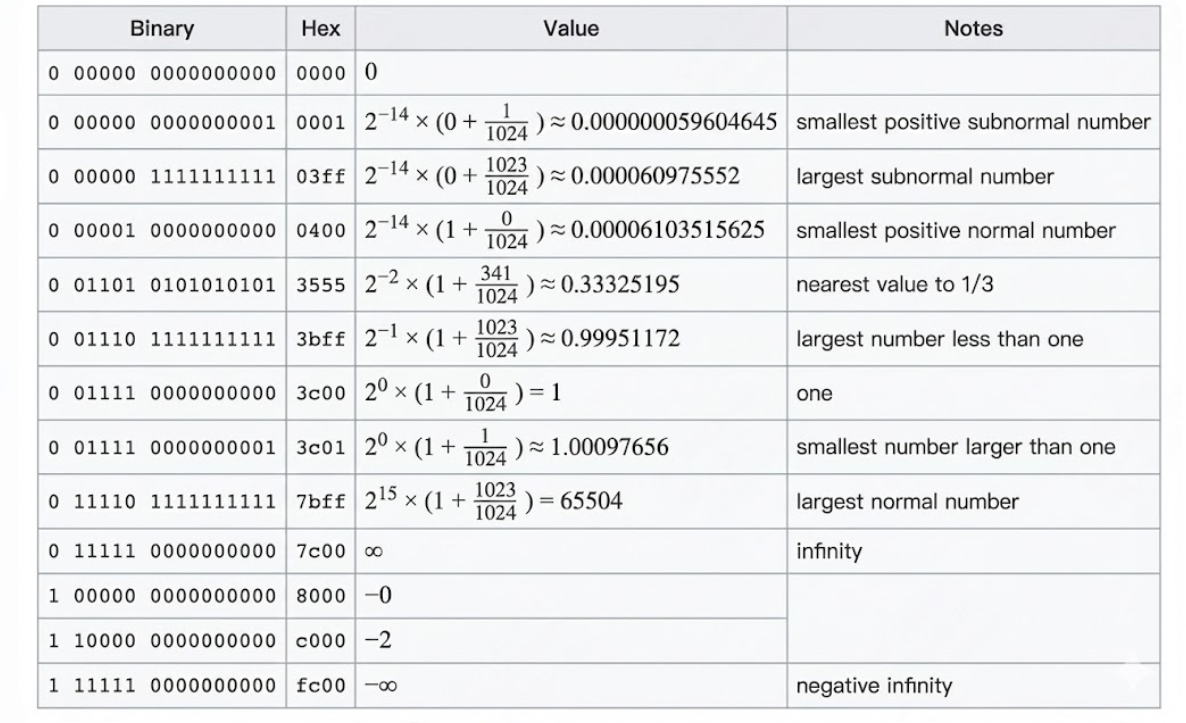
指数最大值:
- 指数 e 最大值 = ( 11110_2 = 30 )(保留最高值 31 用于 inf / nan)
所以:
actual exp=30−15=15
尾数最大:(binary)
1.11111111112=1+(1−2−10)=1.9990234375
最大值:
max=1.9990234375×215
计算:
215=32768
所以:
max≈1.999×32768≈65504
所以 FP16 范围约为:[-65504, 65504]
指数最小正规:
e=1(binary 00001)
实际指数:
1−15=−14
尾数最小正规 = 1.0
min normal=1.0×2−14=163841≈6.1035×10−5
这也是 FP16 的标准数据。
BF16(Brain Floating Point):
| BF16 部分 | 位数 |
|---|
| 符号 | 1 |
| 指数 | 8(与 FP32 一样) |
| 尾数 | 7 |
注意:BF16 的指数位数与 FP32 相同(都是 8 位)!
FP32 bias = 127
BF16 也沿用这一点。
指数最大正规:
e=111111102=254
实际指数:
254−127=127
尾数最大:
1.11111112=1+(1−2−7)=1.9921875
最大值:
1.9921875⋅2127
2ⁱ 转成十进制:
2127≈1.7014×1038
最大值:
BF16max≈3.4×1038
和 FP32 的范围一样。
fp32又被称为单精度浮点表示,是深度学习中标准的精度表示,由32bit组成(4bytes),分为3个部分:
| FP32 部分 | 位数 |
|---|
| 符号 | 1 |
| 指数 | 8(与 BF16一样) |
| 尾数 | 23 |
- 从占用存储角度看,fp16占据2 bytes,bf16占据2 bytes,fp32占据4 bytes
- 从数值表达范围来看:fp32 = bf16 > fp16
- 从数值表达精度来看:fp32 > fp16 > bf16
- 深度学习训练中,一般采用fp32,但出于节省存储,加快训练的目的,我们也会采用混合精度训练,即fp32 + fp16/bf16,这块细节将在下文说明