FlexCheckPoint框架笔记整理
1.问题背景
Checkpoint负责对模型参数、优化器、数据流、随即状态以及徐连所需配置信息进行持久化保存,以便在训练任务出现故障中断后可以重新恢复状态(续训)。
在大模型相同训练任务的不同阶段以及不同任务之间,由于上下游的分布式并行策略以及模型结构可能发生改变往往需要进行checkpoint的转化和迁移,然而很多场景下都是针对不同的模型和任务 case by case手动定制checkpoint切分转换脚本,脚本的开发和维护成本高,且难以复用。
- 预训练场景
- 变换并行策略(无模型结构变化)
- 变换sharding数:由于训练卡量变化,在保持其他并行策略不变的情况下,做sharding reshard,这是比较常见的场景。
- 进行不同并行策略的转换:在dp、pp、tp、sharding、ep之间互转,例如以dp2pp2训练保存checkpoint,而用sharding4做接续训练。
- 训练的ckpt离线转推理做下游评估
- 训练ckpt转推理:合pp和sharding,保留tp的模型结构做推理
- 推理不关心训练的并行方法:推理组只想拿到参数完整的safetensors格式的权重文件,用最原始的模型做推理,而不需要关心,训练用的什么策略,去对组网做特殊处理。
- 跨模型结构的参数融合:
- MOE模型融合不同模态的专家
- 训练中途括tokenizer的词表维度,训练段Linear参数的shape发生变化
- fused_qkv,fused_ffn在不同tp并行数下,需要重排做二次划分。
- fused_qkv,fused_ffn转非fused_qkv,fused_ffn做训练。
- 变换并行策略(无模型结构变化)
- 开源场景
- 飞桨的checkpoint数据使用pickel存储,是pdparam格式,不支持safetensors格式,有一套UC框架,是直接训练结束时保存成safetensors格式,但无法直接转换。开源时每次要准配两份权重,并且要case by case写转换脚本。
- 部分参数存储形式和开源社区习惯不同,例如Linear的weight存储transpose形式等。
因此为了实现解决上述问题,需要一套新的checkpoint系统来降低转换开销,支持任意并行策略的互相转换,支持参数融合,模型结构的改变,并且在线转换的时间控制在秒级。
2.FlexCheckpoint设计整体框架
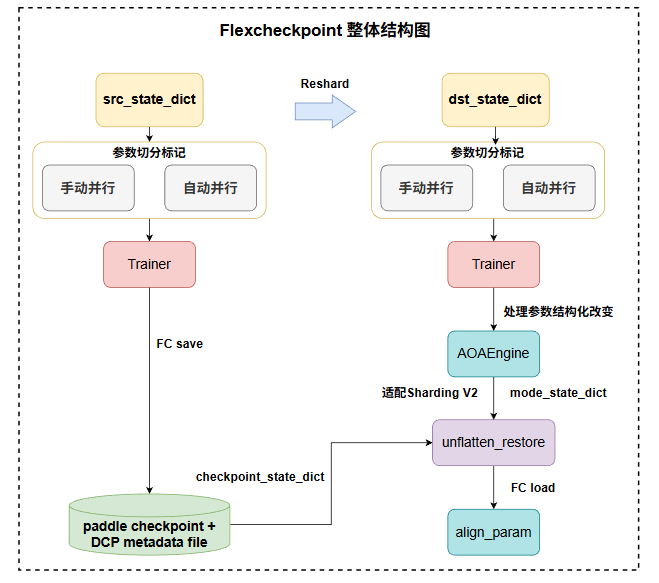
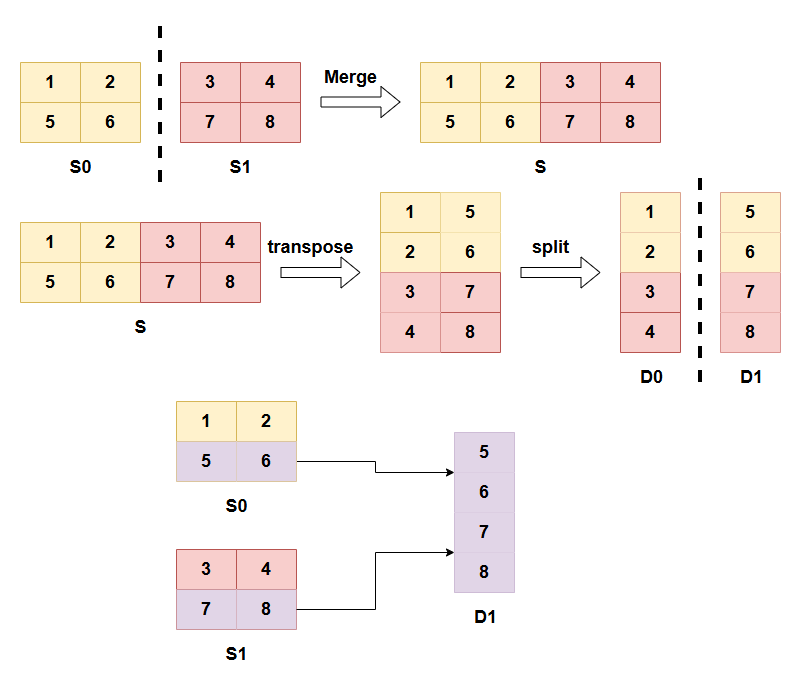
以上是FC的整体架构图,主要由两个部分组成,一部分是DCP,另一部分是AOA。
考虑到DCP协议存储和转换过程与分布式策略解耦,其灵活性和通用性更强,支持零冗余加载,并且能兼容飞桨自动并行生态,因此FC的底层复用DCP协议实现切分转换,在切分标记上,FC借鉴Megatron的思想,由用户在Layer中标记ShardedStateDict,与Megatron一样,如果用户调用框架提供的分布式API,例如像ColumnParallel、RowParallel、VocabEmbedingParallel等并行组件,无需用户做额外操作,框架自动标记好。
同时为了实现跨模型结构转换,比如参数的一些合并、拆分、转置、替换等等,我们进一步提出了AOA(all-in-One-arrow),该协议允许用户在单卡视角下使用非常简洁的箭头语言表达跨模型结构转换的信息,而不需要关心参数的具体切分方式。AOA提供了7种操作原语来表达所有的转换操作,包括split、merge、rename、add、remove、transpose、cast,用户只需要用简单的箭头语言表达参数转换逻辑,AOA协议会自动将这些语义翻译成底层参数切片的转换操作,从而实现跨模型结构转换的机制。
3.跨并行策略参数转换(DCP)
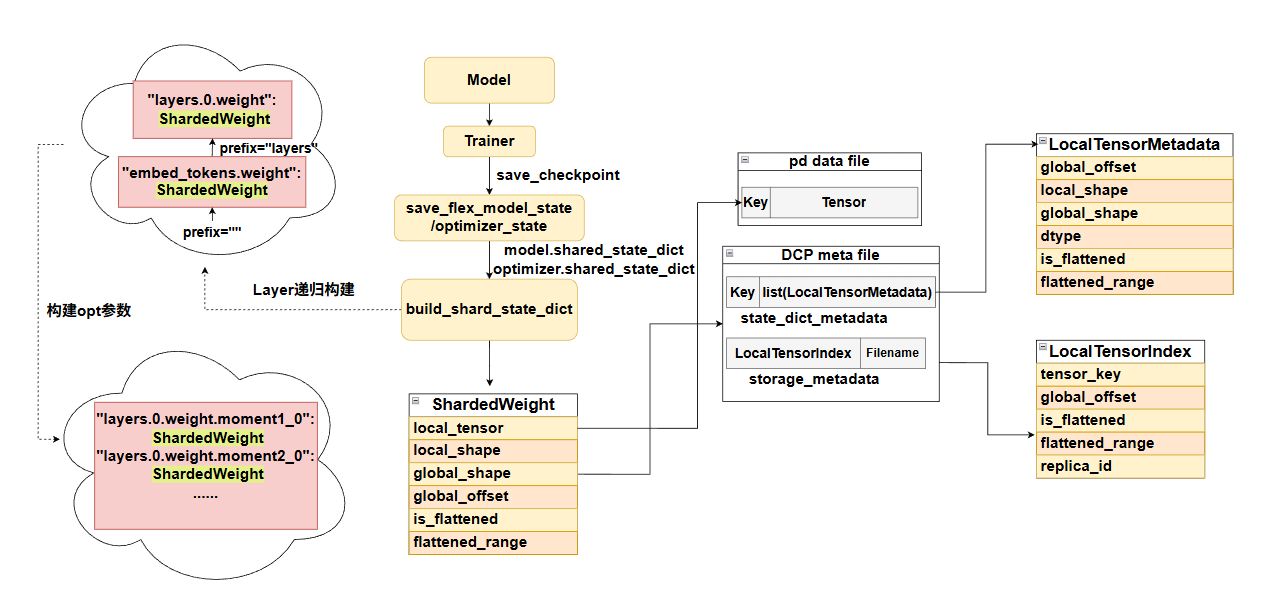
DCP Save checkpoint
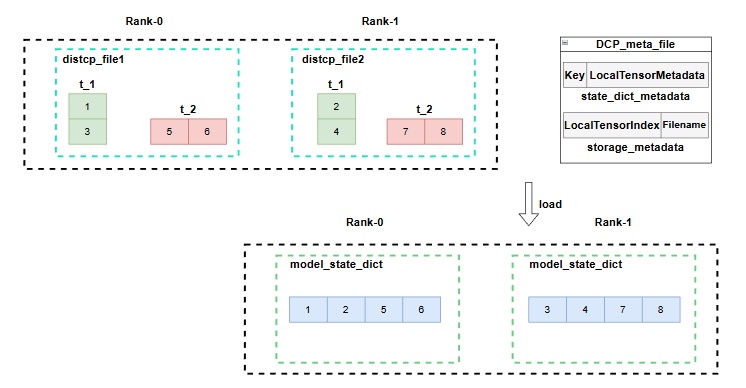
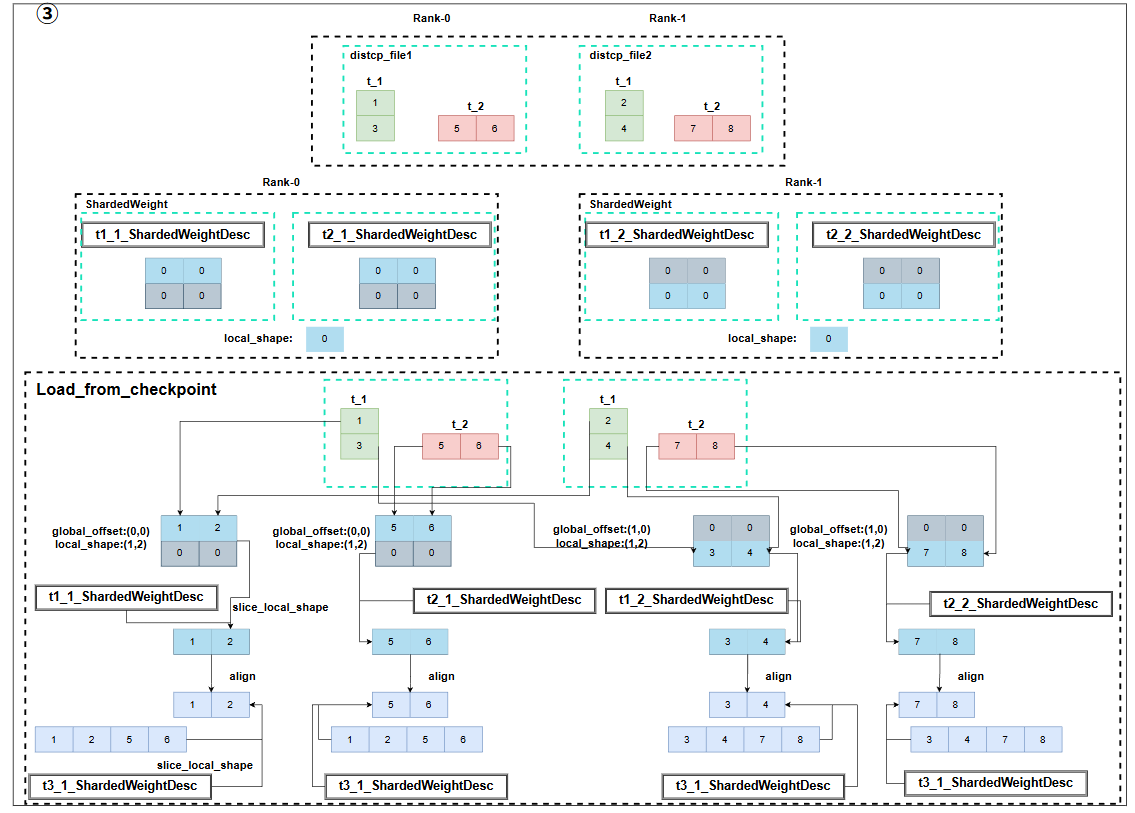
在开启save_checkpoint_format="flex_checkpoint"时,模型训练到保存点时,会调用shared_state_dict方法,该方法直接写在Layer类中,所以所有model都有此方法,同时在一些特殊的分布式layer中,如:ColumnParallel、RowParallel、VocabEmbedingParallel中适配了该方法,这些方法都会调用build_shard_state_dict方法来创建一个包含丰富信息的ShardedWeight,通过这个信息,我们就能知道某个param是否做了切分,以及可以从全局tensor中定位到它的具体切片位置。在保存参数文件时,还是会恢复到tensor来保存,但是会将shardedweight记录的tensor的所有信息用LocalTensorMetadata给记录下来,为后续load操作时,使用meta信息恢复src_tensor的切分状态信息的操作奠定基础。注意state_dict_metadata保存的是param名为key的所有分片
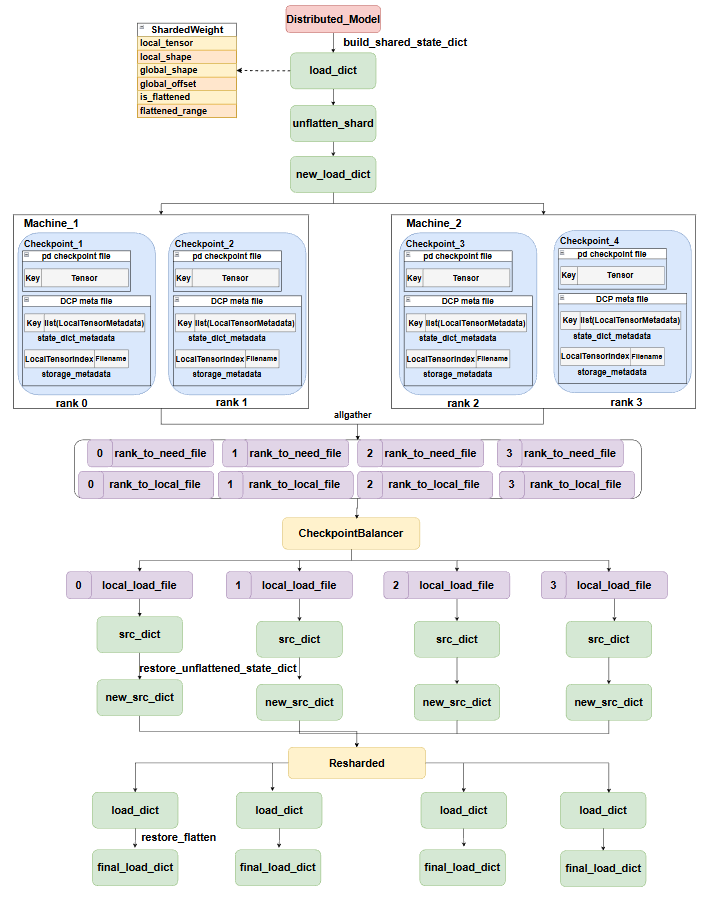
DCP Load checkpoint
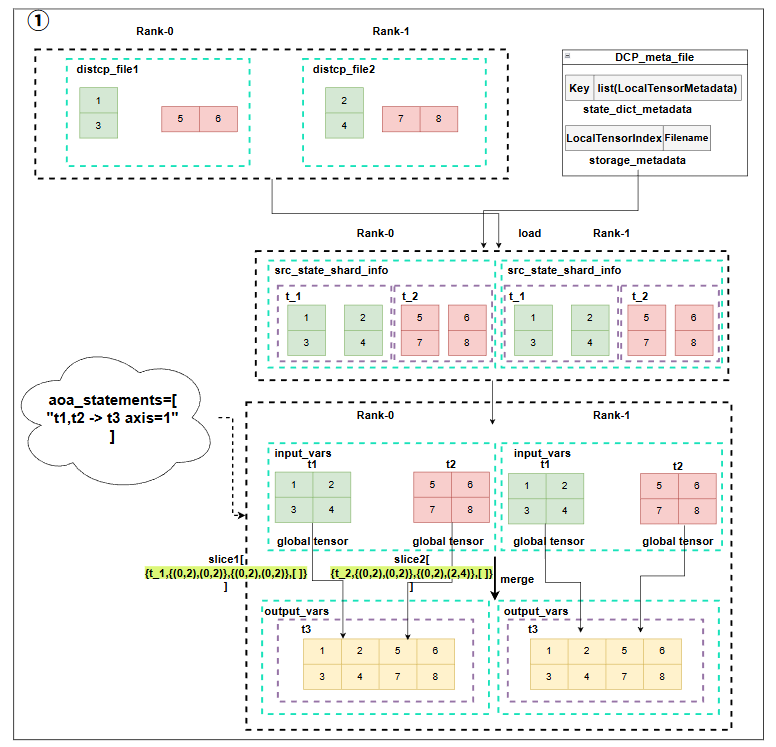
DCP load checkpoint的流程如上图所示,首先会调用model和optimizer的shared_state_dict把param都转化成ShardedWeight形式,然后会对load_state_dict一些flatten的param做一个unflatten,这里做unflatten的目的是,load_state_dict中的tensor后续要根据local_map和global_offset来接收src_state_dict中的param,此时tensor是一维的,而记录的local_shape是多维的,如果这里不做unflatten,后续根据local_shape和global_offset恢复时,就无法正确align src到dst,所以这里主要做的是恢复最小多维形状,并更新local_shape和offset。这里要保存原来的信息,最后要恢复,因为model此时就需要flatten的param,此处只是为了加载数据才做了unflatten紧接着会根据所有的load_state_dict判断加载这些param需要文件得到rank_to_need_file,同时读取path对应的checkpoint,得到当前rank本地能够拿到的文件,每个machine不一样,同一个machine因为path一样,所以获取的也一样。此时所有rank都拿到了自己需要读取的文件和实际持有的文件,但为了减少显存压力,以及均衡负载,会用一个CheckpointBalancer来分配每个rank实际读取的文件,即local\_load\_file,所以可能会存在一些param并没有在本rank,所以最终读取param可能需要与其它rank通信获取全部的param,而这个操作就在Resharded中进行。**注意到src_state_dict也要把一些flatten的param做一个unflatten,并且这里还需要restore,也就是同样要像load_state_dict一样,恢复成最小的多维,同时此时如果做了padding,则padding部分的数据需要从其它rank的参数分片中load,此时其它rank的这个参数的分片也一定是flatten的状态,所以计算一下最小多维的一维的大小以及一维offset,并创建一个新的ShardedWeight,这个新的ShardedWeight会调用load接口,此时新的ShardedWeight就是load_state_dict,并且用旧的ShardedWeight作为src_state_dict(只在reshard_needed_tensors范围内,因为只有这些flatten的需要恢复多维,并且获取的数据也只会从flatten数据中获取),load后,再做reshape恢复成多维,此时所有的src_state_dict都为多维,可以和load_state_dict正常取交集,并赋值数据了。**最后根据之前保存的数据,恢复load_state_dict的fatten的param。
1.DCP_meta_file
DCP_meta_file主要的作用有两个:
LocalTensorMetadata,是一个是用来记录每个key,以及key对应的一些重要信息的。比如通过global_offset、local_shape、global_shape这三个参数我们就能知道当前这个tensor在全局视角下的具体切片位置,从而在不同的并行策略下做reshard,来让新的组网的每个tensor能够正确加载原来ckpt中的数据。而dtype则是需要知道是否要做cast,转换数据类型。flattened_range和is_flattened则是用来记录是否有被flatten的参数,如果有,则记录它flatten的范围,用�于后续load参数时从正确src_tensor加载optimizer的数据,因为在DanamicOptimizerShardingV2中,optimizer的参数会被展平,然后分到不同的卡上,如果只记录local_shape,无法知道分片信息。
LocalTensorIndex,主要作为Filename的索引,指明每个tensor存在哪个权重文件里,首先tensor_key和global_offset可以构成唯一标识符,这里同样存了一下flatten相关的参数,replica_id,主要是用来标识同样的param存在不同的文件中,这个主要是为了支持locally load,即同一份参数在多张卡上被使用,直接保存多份参数在每张卡的文件中,这样在load的时候,可以直接load自己rank对应的那个distcp文件,而不需要卡间通信。
2.DCP save load 关键函数
1.sharded_state_dict函数
以下是在Layer中定义的sharded_state_dict函数,是最里层的实现,因此对于一般的层来说直接继承这个方法即可,首先会获取原始的state_dict,通过build_sharded_state_dict构建ShardedWeight,一般是默认没有shard_rules的,只有要做TP切分的,才会传这个参数,即沿着哪个axis做切分,注意这里处理的是只包含自己这一层的参数,创建之后更新sharded_state_dict,然后递归处理子层,从而逐渐加上prefix。
def sharded_state_dict(
self,
structured_name_prefix: str = "",
) -> ShardedStateDict:
"""Recursively builds a sharded state dictionary for the model and its sub-layers.
Args:
structured_name_prefix: Prefix to prepend to all tensor names for hierarchical naming.
Returns:
Dictionary mapping tensor names to ShardedWeight.
The dictionary contains both the current layer's parameters and all sub-layer parameters.
"""
sharded_state_dict = {}
# Get current layer's state dict (without sub-layers)
state_dict = self.state_dict(
structured_name_prefix="", # We handle prefixing ourselves
include_sublayers=False,
)
# Convert to sharded state dict
current_sharded_dict = build_sharded_state_dict(
state_dict=state_dict,
shard_rules=None, # No tensor parallelism rules by default
prefix=structured_name_prefix,
)
sharded_state_dict.update(current_sharded_dict)
# Recursively process sub-layers
for layer_name, layer_item in self._sub_layers.items():
if layer_item is not None:
sub_sharded = layer_item.sharded_state_dict(
structured_name_prefix=f"{structured_name_prefix}{layer_name}.",
)
sharded_state_dict.update(sub_sharded)
return sharded_state_dict
以下是一个行切的Layer的例子,通过传入对应参数以及需要tp切分的维度,即可得到包含全局TP切分信息的ShardedWeight。
def sharded_state_dict(
self,
structured_name_prefix: str = "",
):
state_dict = self.state_dict()
return build_sharded_state_dict(
state_dict, {"weight": 0}, structured_name_prefix
)
2.build_sharded_state_dict函数
这个函数就是用来构建ShardedWeight的接口函数,通过传入进来的tensor和对应的shard_rules来判断该参数在全局是否做了TP切分,如果是则根据当前tensor的local_shape和所在的rank_id,来构建global_offset和global_size的信息,从而得到具有全局视角的ShardedWeight的tensor切片,而prefix则是用来构建key的前缀;如果是非TP的,则就会调用Replicate,直接创建,global_size和local_size相同的tensor。
def build_sharded_state_dict(
state_dict: dict[str, Tensor],
shard_rules: dict[str, int] | None = None,
prefix: str = "",
) -> dict[str, ShardedWeight]:
"""Converts a regular state dict to a sharded state dict based on sharding rules.
Args:
state_dict: The original state dictionary containing tensors
shard_rules: Dictionary mapping tensor names to their sharding axes.
If None, treated as empty dict (no tensor parallelism).
prefix: Optional prefix to prepend to all tensor keys
Returns:
Dictionary with the same keys as input but values converted to ShardedWeight
or regular Tensor based on sharding rules.
Note:
Tensors not in shard_rules will be wrapped as non-sharded ShardedWeights.
"""
shard_rules = shard_rules or {}
sharded_state_dict = {}
for key, tensor in state_dict.items():
full_key = f"{prefix}{key}" if prefix else key
if key in shard_rules:
# Apply tensor parallelism sharding
sharded_state_dict[full_key] = (
make_tp_sharded_weight_for_checkpoint(
key=full_key,
tensor=tensor,
tensor_parallel_axis=shard_rules[key],
)
)
else:
# Create regular sharded tensor (non-tensor-parallel)
sharded_state_dict[full_key] = make_replicated_sharded_weight(
key=full_key,
tensor=tensor,
)
return sharded_state_dict
3._unflatten_shards函数
def _unflatten_shards(flat_shards, comm_method):
load_dict, padding_info = {}, {}
for key, flat_shard in flat_shards.items():
local_shape = flat_shard.local_shape
flat_start, flat_end = (
flat_shard.flattened_range.start,
flat_shard.flattened_range.stop,
)
min_slices, _, _ = minimal_nd_slice(local_shape, flat_start, flat_end)
min_flat_start, min_flat_end = flat_range_in_min_slice(
local_shape, min_slices, flat_start, flat_end
)
min_shape = tuple(e - s for s, e in min_slices)
min_offset = tuple(
g_off + s[0]
for g_off, s in zip(flat_shard.global_offset, min_slices)
)
min_numel = math.prod(min_shape)
flat_numel = flat_end - flat_start
if min_numel == flat_numel:
tensor = flat_shard.local_tensor.reshape_(min_shape)
load_dict[key] = ShardedWeight(
key=key,
local_tensor=tensor,
local_shape=min_shape,
global_shape=flat_shard.global_shape,
global_offset=min_offset,
is_flattened=False,
flattened_range=None,
)
else:
pad_tensor = paddle.zeros(
min_shape, dtype=flat_shard.local_tensor.dtype
)
load_dict[key] = ShardedWeight(
key=key,
local_tensor=pad_tensor,
local_shape=min_shape,
global_shape=flat_shard.global_shape,
global_offset=min_offset,
is_flattened=False,
flattened_range=None,
)
padding_info[key] = {
"src": pad_tensor,
"flat_shard": flat_shard,
"slice_range": (min_flat_start, min_flat_end),
"min_shape": min_shape,
}
return load_dict, padding_info
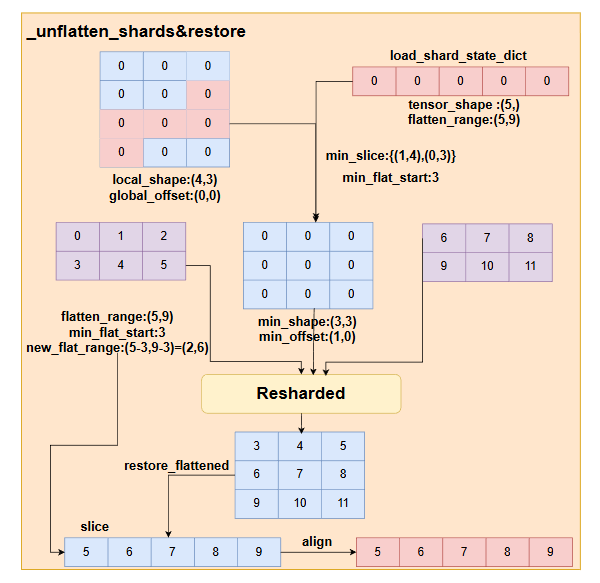
对于load_state_dict中的flatten的param,首先根据local_shape,global_offset,以及它的faltten_range,计算出该一维向量恢复到多维向量需要的最小shape,并计算全局offset,用这个新的tensor去load param的数据,最后全部load结束后,将temp param做flatten,然后根据保存的new_flat_range切分出原来load_state_dict需要的那部分参数,并赋值给原来的flattened_param,如果flattened_param本身就能构建一个mini_shape大小的多维tensor,则直接reshape,并load数据,最后再做一个flatten即可。
这里计算min_slice的方法也很简单,首先判断flatten_range的start和end在多维坐标的位置,然后每个维度做对比,如果维度是第一个维度,则slice为(start,end+1),因为最外面的维度start一定小于end。否则:1.上一个维度的start和end相等,说明当前这个维度对于上一个维度来说是一个一维的切片,则slice为(start,end+1);2.上一个维度的start和end不相等,则直接取这个维度的整个大小,即slice(0,shape[axis]),axis表示当前这个维度。
4.restore_unflattened_state_dict函数
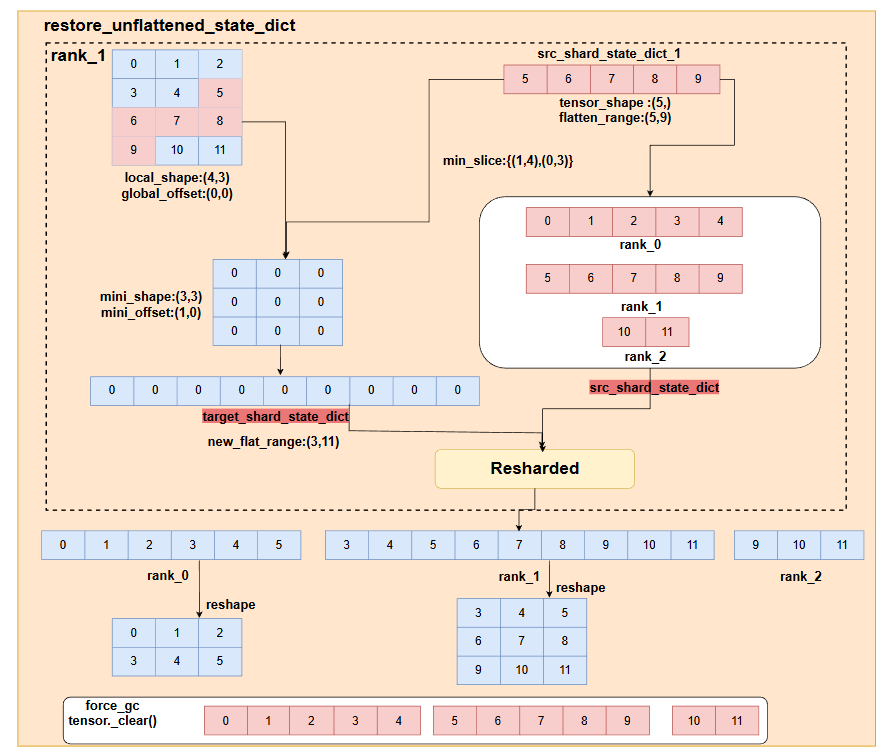
restore_unflattened_state_dict主要是用来对src_shard_state_dict里面flatten的参数进行进行reshape,因为此时load_shard_state_dict是多维的,如果src不恢复多维,无法计算二者的重叠部分,从而load数据。而在做reshape时,像在Zero1中,对所有param做flatten,并且拼接后做sharding,这时候param的切分是不均匀的,如图所示,它恢复形状的时候,无法直接reshape,所以我们首先要计算它恢复到多维大小时的最小切片,从而创建一个zero的tensor,并将它flatten,因为当前这个param的所有切片,在所有rank上都是flatten的,所以我们需要将这个新的tensor展平,作为此时的load_shard_state_dict,并且之前旧的tensor就作为此时的src_shard_state_dict,调用load接口,将需要的数据给load到这个临时的tensor中,最后将其reshape,并将它作为新的src_shard_state_dict,之前旧的src_shard_state_dict就直接清除掉。
3.CheckpointBalancer类
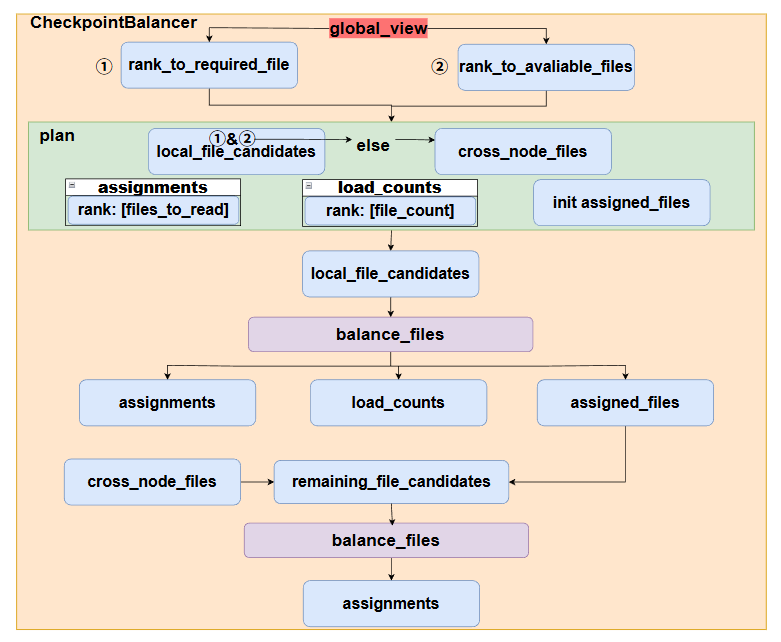
如图所示为CheckpointBalancer的核心架构,首先输入的是rank_to_required_file和rank_to_aviliable_file,两个表都是全局视角的列表,里面包含的键值对分别表示,rank当前加载所有的param数据需要的file和rank当前本地可以获取的file。初始化的assignments用来记录每个rank实际需要load的file,而load_counts用于记录当前rank已经分配的file数,从而做负载均衡,assigned_files则是直接用来记录已经分配的文件,确保每个文件仅仅被一个rank加载。
整个执行流程在plan中进行,首先会对file进行一个划分,如果是rank需要的且rank本身就能获取的file定义为local_file_candidates,先用balance_files处理,来负载均衡地分配文件(local_file_candidates的处理是确保了rank本地需要且rank本地有的文件优先分配,减少通信)。紧接着对于cross_node_filse做一个过滤,过滤到已经在本地分配过了的文件,最后还剩的文件,剩余文件直接按照哪些rank上有,则做一个file-rank的映射得到remaining_file_candidates,再次调用balance_files进行分配(注意cross_node_files都是本地rank没有,但是需要的file,所以可能存在某个file,所有rank上都没有,因此需要做一个检查。)。
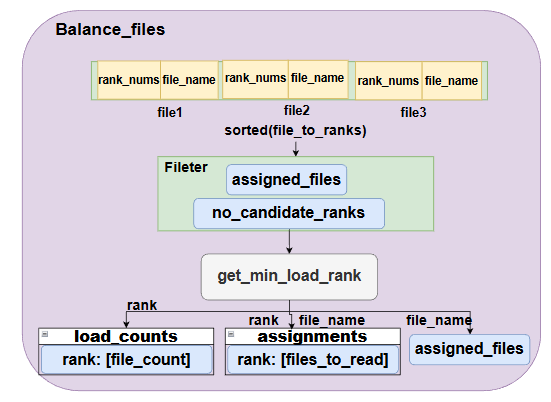
Balance_files的分配方法主要是首先按升序方法,先以当前file被分配到的rank数排列,如果相等,则按file_name排列**这里从小到大排序主要是为了在将可�选则范围小的file先分配,否则若先分配可选范围大的,则容易造成可选范围小的file对应的那些rank负载更重。**然后对排序后的file-ranks对遍历,每次在ranks中选择一个当前分配最少的,也就是load_counts最小的文件,把这个file分配给它。
4.Resharder类
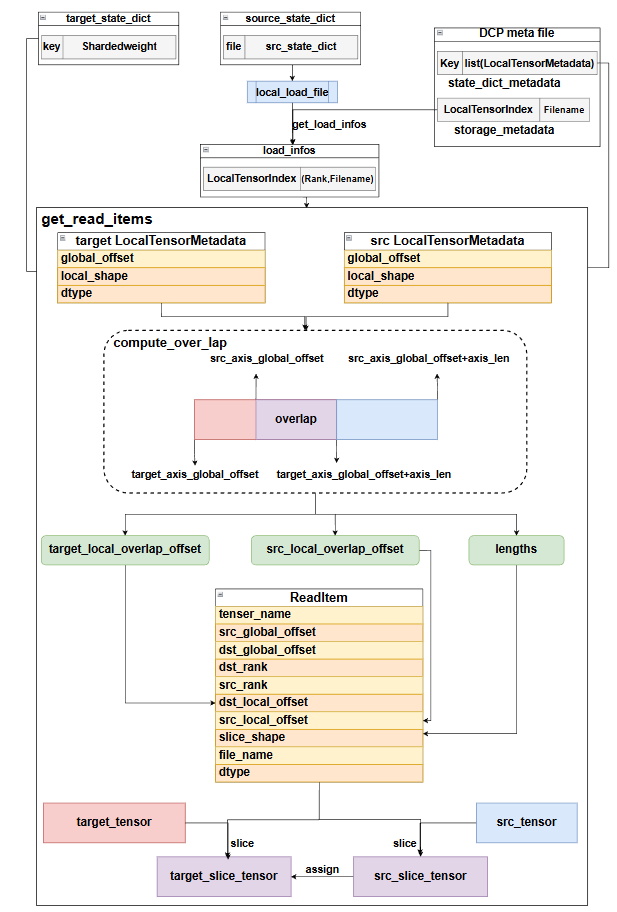
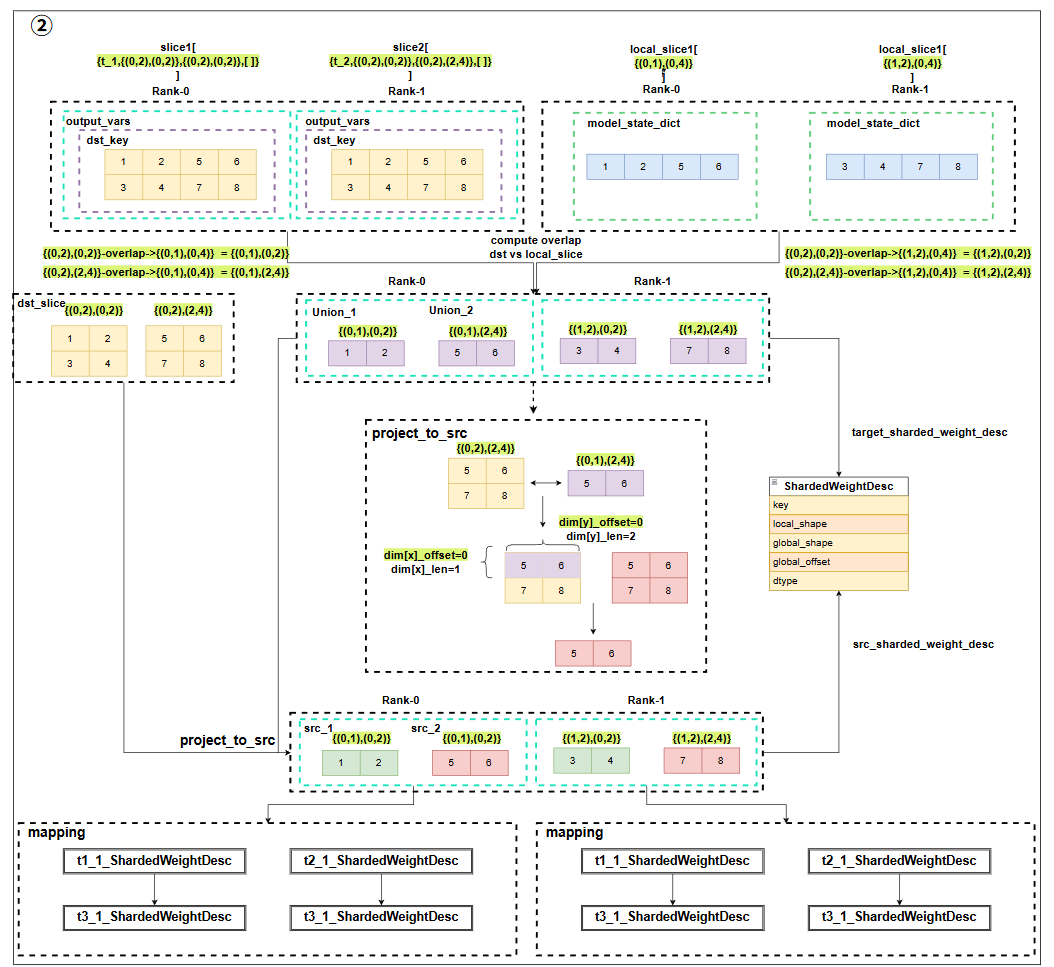
首先根据当前rank上的source_state_dict获取当前rank负责load的文件,然后使用get_load_infos获取load_infos,里面记录了加载某个param要从哪个rank上读哪个文件,接着根据metafile里面保存的state_dict_metadata来构建src_localtensorMetadata,以及target_state_dict获取target_localtensorMetadata(注意这里不需要src_state_dict的数据,因为这里只是算重叠部分,还没有加载数据)通过这两个信息,即可算出二者在多维的全局tensor中的重叠部分,并计算各自的local_overlap_offset,这个是因为二者切分重叠部分都是基于自己的tensor在全局的分片状态来切分的,当选取重叠分片的时候,global_offset小的那个分片得知道overlap分片相对当前自己的global_offset的位移,才能切出overlap部分,而global_offset大的那个分片直接从global_offset开始切就行,即local_offset=0。接着定义一个ReadItem,保存了获取重叠分片的必要信息,以及读取对应的param数据应该从哪个src_rank读,而应该发送给哪个dst_rank去load这部分数据。最后批量处理ReadItem从src_tensor和taget_tensor分别切出对应overlap的部分,经过不同的通信后,做assign操作�,完成load数据。
5.Communicator类
三大Communicator类
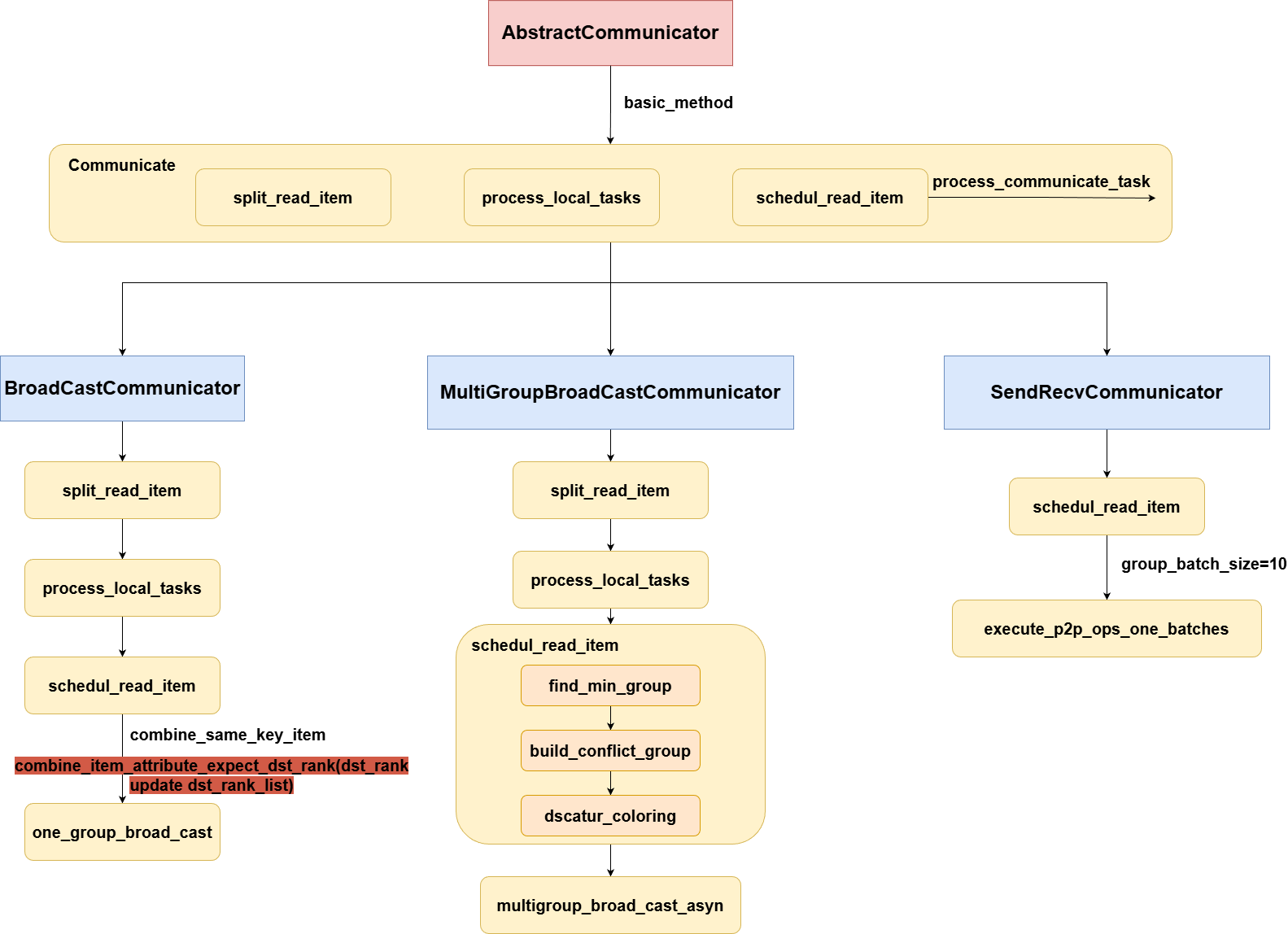
当前有三种Communicator类,都是基于AbstractCommunicator延申出来的,分别是BroadCastCommunicator,MultiGroupBroadCastCommunicator,SendRecvCommunicator。
问题简介:之前load save实现方式是,首先我们会根据source_state_dict和target_state_dict,以及它们的local_shape,global_offset得到它们重叠的部分,然后根据重叠的部分,定位到src和dst需要切片的部分,这部分在src和dst大小相同,也是后续通信需要赋值的,这样我们会得到一个ReadItem,这个ReadItem就记录了,dst_rank需要从src_rank获取哪部分src_tensor的数据,来赋值给dst_tensor,通信方式是整个group进行broad cast,每次处理一个ReadItem。
可以 发现这里就有一个问题,首先任何情况下都做broad cast广播,如果当前通信过程,大量都是某个rank只需要从另一个rank获取数据,其它rank都无关,这其实就造成了通信冗余,并且每次只处理一个ReadItem,不进行任何分组,效率也是很低的。
但是我们不能盲目地直接改成p2p通信,因为我们知道通信时间上看,p2p的通信是要远高于broadcast的,但是注意在大量独立的两�两通信的场景下,我们是可以异步执行这些通信的,所以我们需要因场景而异。
首先BroadCastCommunicator,这个是一个在单一分布式策略下使用的communicator,即group只有一个,此时相比于原来的逐个处理,我们将相同的tensor_name的ReadItem给放在一组,进一步把ReadItem除了dst_rank以外其它属性相同的ReadItem做进一步的group分组,然后dst_rank此时更新成多个,这一步的目的就是将需要同一片src数据的dst_tensor聚合在一起,这样做一次broadcast就可以让每个dst_rank都拿到数据,而不是像之前那样一个ReadItem一个ReadItem处理,提高了效率。
其次是GroupBroadCastCommunicator,这个的处理方式最主要的改变在,不再是全局group通信,而是在保证src_rank和dst_rank都包含在group内时,求一个最小的group(注意我们并没有在这时候去动态新建group,而是复用已经存在的group,去找一个最小group,因为动态新建group反而会带来更大的开销),然后对这些group创建一个conflict_group,主要是某个rank同时存在于不同的两个group,则这两个group就是conflict的,因为我们知道某个rank做broadcast没办法同时发送和接收数据,接着我们用了dscatur_coloring(degree of scaturation)图染色法,来根据饱和度,动态自适应地找到一组最小的解,即将conflict的group进行划分,并将非conflict的group聚合,找到一组最小划分方法。这样划分之后,每个batch里面的group都是非conflict,因此可以做异步的broadcast,极大提升效率,并且在之前找最小group也能极大缩小broadcast的范围,减少资源浪费。
最后是SendRecvCommunicator,这个是在需要大量的p2p通信的场景下使用的,因为p2p的通信是可以异步的,所以我们设定了一个group_size,默认为10,每10个数据一处理,处��理完后即可删除中间变量,即发送和接收数据对src_tensor和dst_tensor进行slice时产生的中间变量。
Degree of Saturation图着色算法
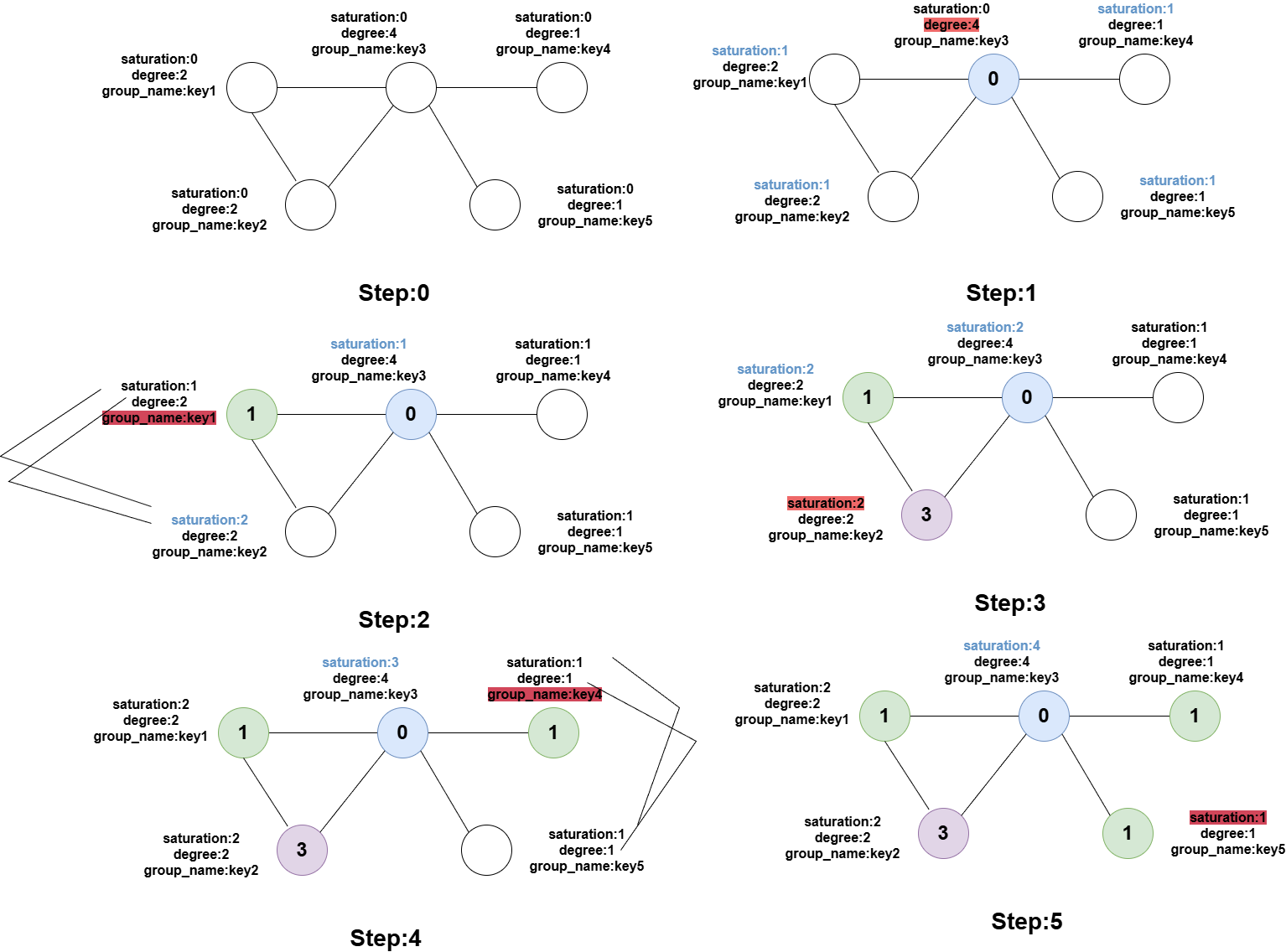
定义饱和度saturation(该点的邻居节点已经使用过的颜色数)、度数degree、节点名称node name(这里对象是group)。
算法流程如下:
1.首先在未染色的集合中,选择saturation最大的进行染色,若saturation都相同,则选degree最大的,如果还是相同,则选key做小的跳出僵局。
2.每次染色判断当前节点的邻居结点已经用过的颜色,颜色从0开始往上加,直到选到没用过的颜色进行染色。从未染色的集合中剔除该结点。
3.更新该节点周围的邻居结点的saturation,都增加1,并且当前结点的每个邻居结点的邻居节点已经用过的颜色集合中增加一个当前结点的颜色。
4.重复1~3直到全部染色完毕。
6.DynamicOptimizerShardingV2示例
6.1 FlexCheckpoint示例
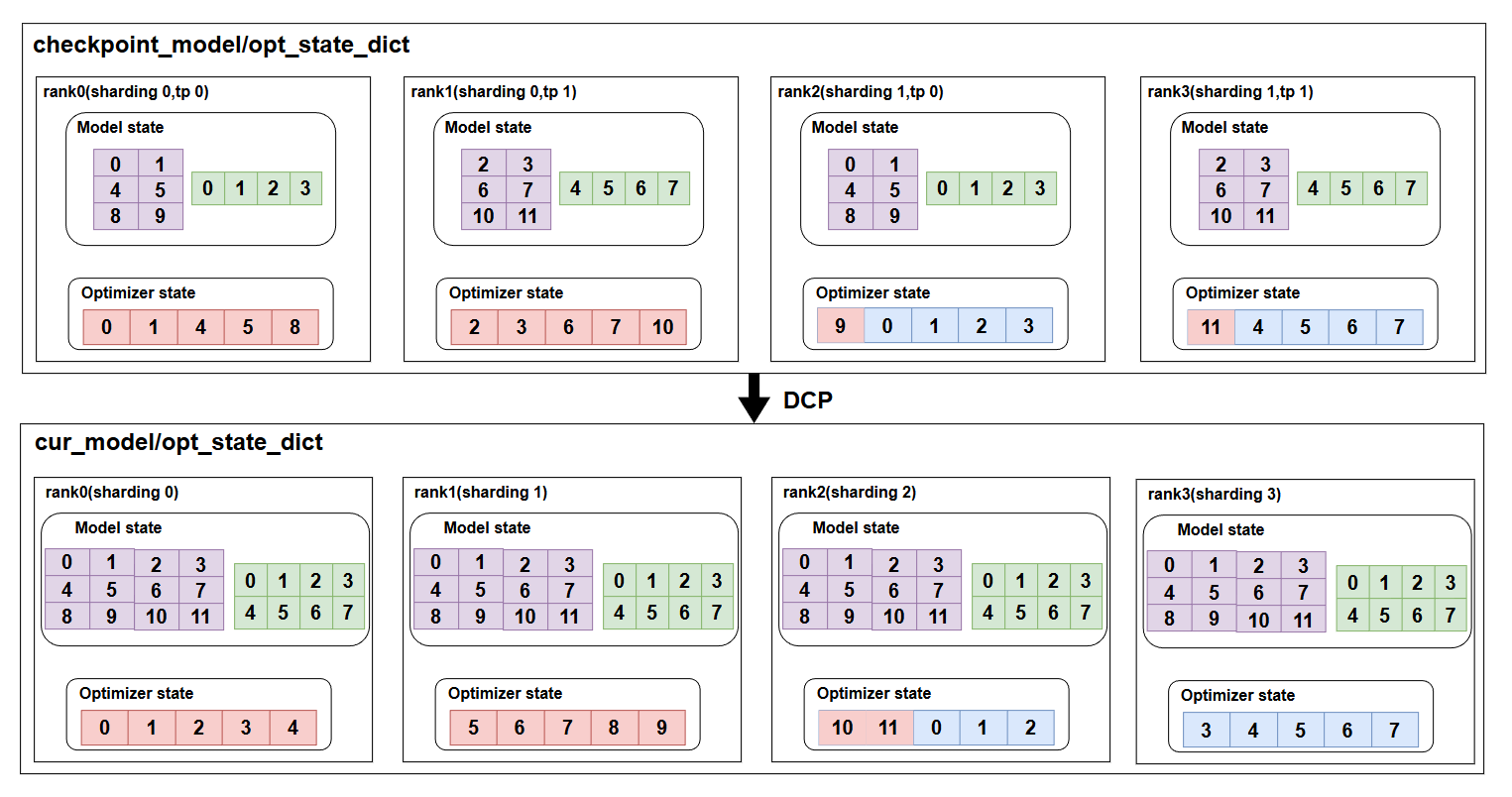
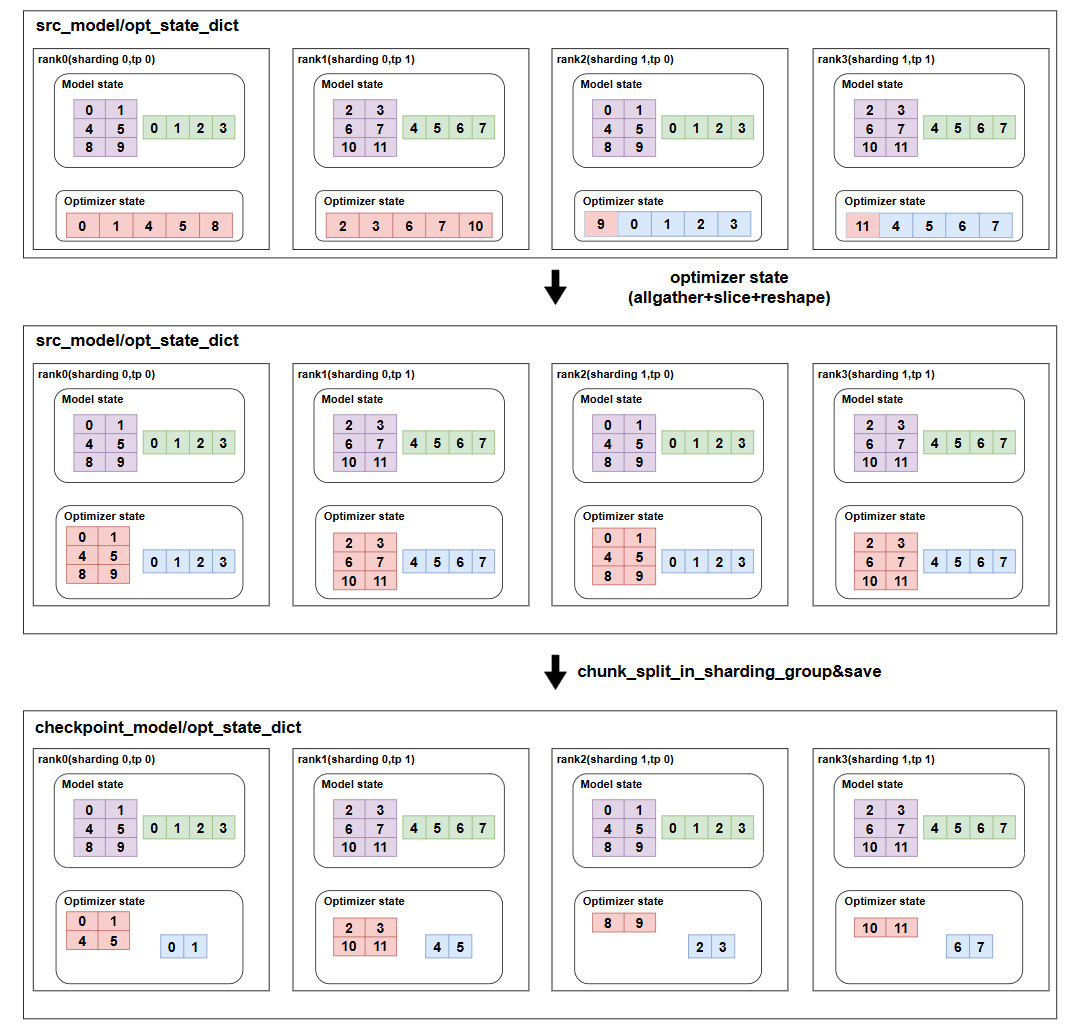
首先我们一个比较常见的场景,Zero1的一种实现是把当前rank上的param全部拼接起来并按一维展开,然后和sharding_rank进行一个均匀切分,这里是逻辑切分,是为了分配optimizer的,实际的param都还是保存的全量的,如上图所示,我们训练保存的checkpoint文件是tp2sharding2,现在要转换到sharding4,具体转换步骤如下:
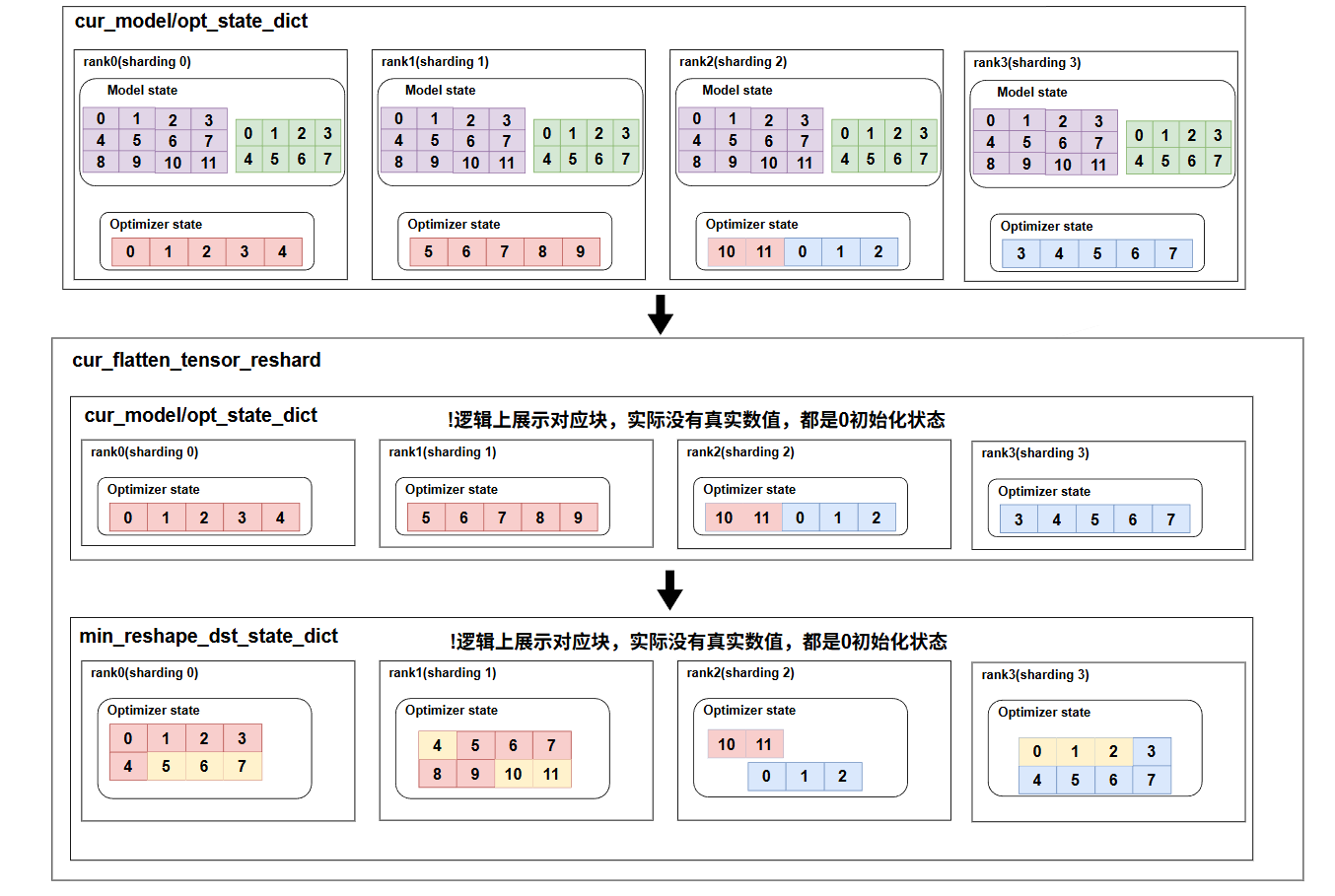
首先我们需要对当前optimizer_state_dict被flatten的参数进行一个维度恢复,这里是为了恢复到最小可表示的shape,比如这里rank0上的参数,表示第一行的四个元素和第二行的一个元素,无法直接用global_offset和local_shape来表示,也就无法reshape成二维,所以需要计算它的min_reshape,即填充三个元素,得到原来local_shape的前两行,这时候就可以用globle_offset(0,0)和min_shape(2,4)来表示这个块了,所有的都要计算对应的min_reshape,对于min_reshape=当前flatten范围表示的切片大小的,比如rank2表示的opt的参数,则直接reshape,不需要做处理。
这里可能读者会疑惑,为什么不直接一维读数据,因为我们无法保证,checkpoint里面一定是sharding的状态,还有可能是非sharding,这时候src的opt参数都是多维的,如果直接用一维的dst_opt参数去读,是无法正确计算重叠面积的。也可以直接用local_shape大小的数据块直接去读,因为这里的切片范围就��是相对于local_shape去切的,所以一定在local_shape范围内,但这样的话就会加载一些不必要的数据,这里做了一个最小开销的处理。
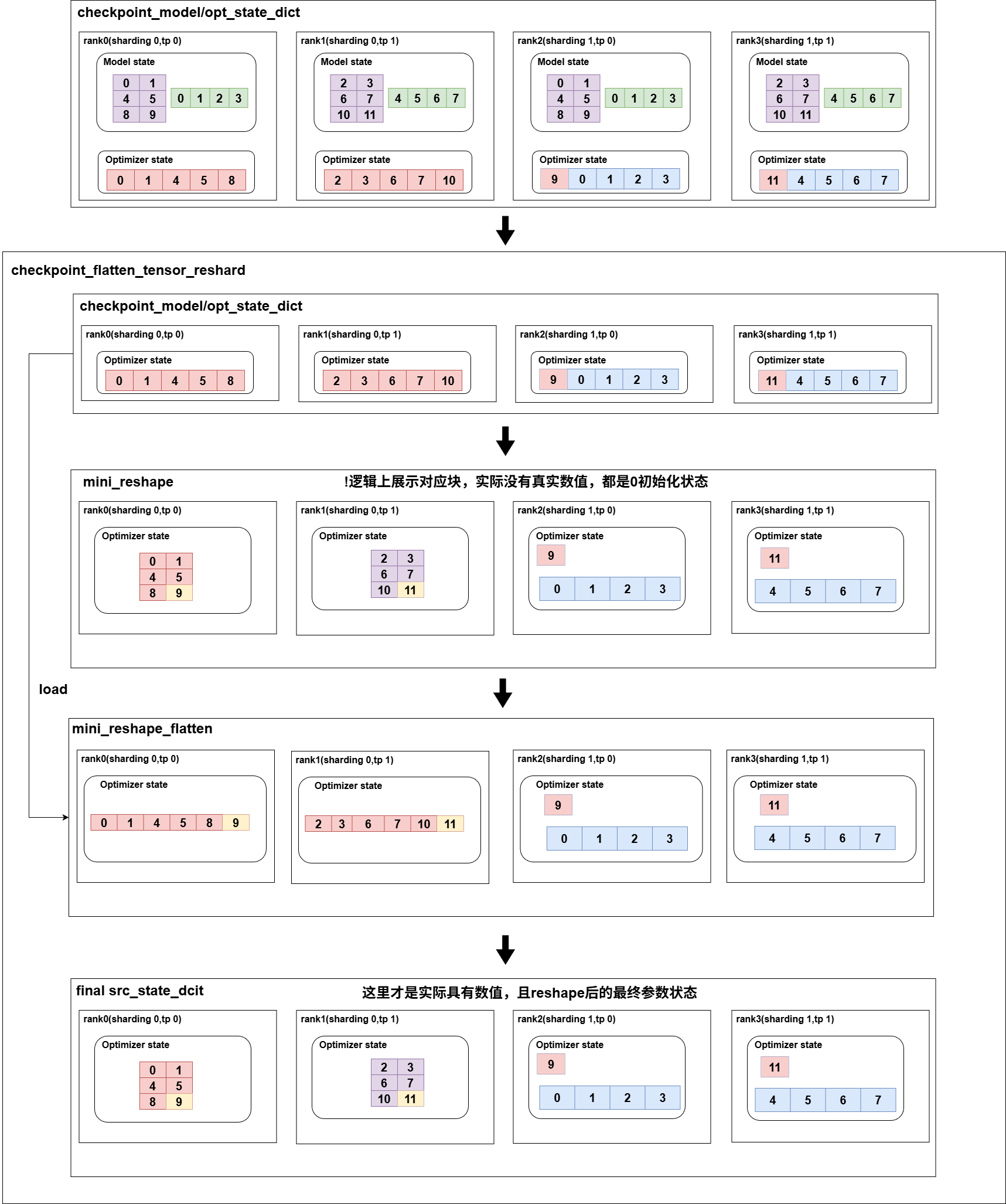
既然dst_opt的参数需要reshape,那么同样checkpoint的数据也需要reshape到多维度,这里同样我们会计算min_shape,但是注意,我们还要把min_shape给展平,初始化的是flatten的参数,因为我们checkpoint里面保存的是flatten的参数,想要load数据也只能用flatten的,而对于rank2,rank3不需要load数据,就不变,而rank1,rank2的数据会调用load_state_dict接口去从checkpoint文件中读取数据,得到min_shape的最小表示数据,我们最终的目的就是把checkpoint里面的数据reshape到多维度,所以将最终load下真实数据的opt参数,再reshape,并且直接覆盖掉原来的src的opt参数,即得到了最新的多维的opt参数,从而可以和dst的opt参数正确计算重叠部分,并load数据。
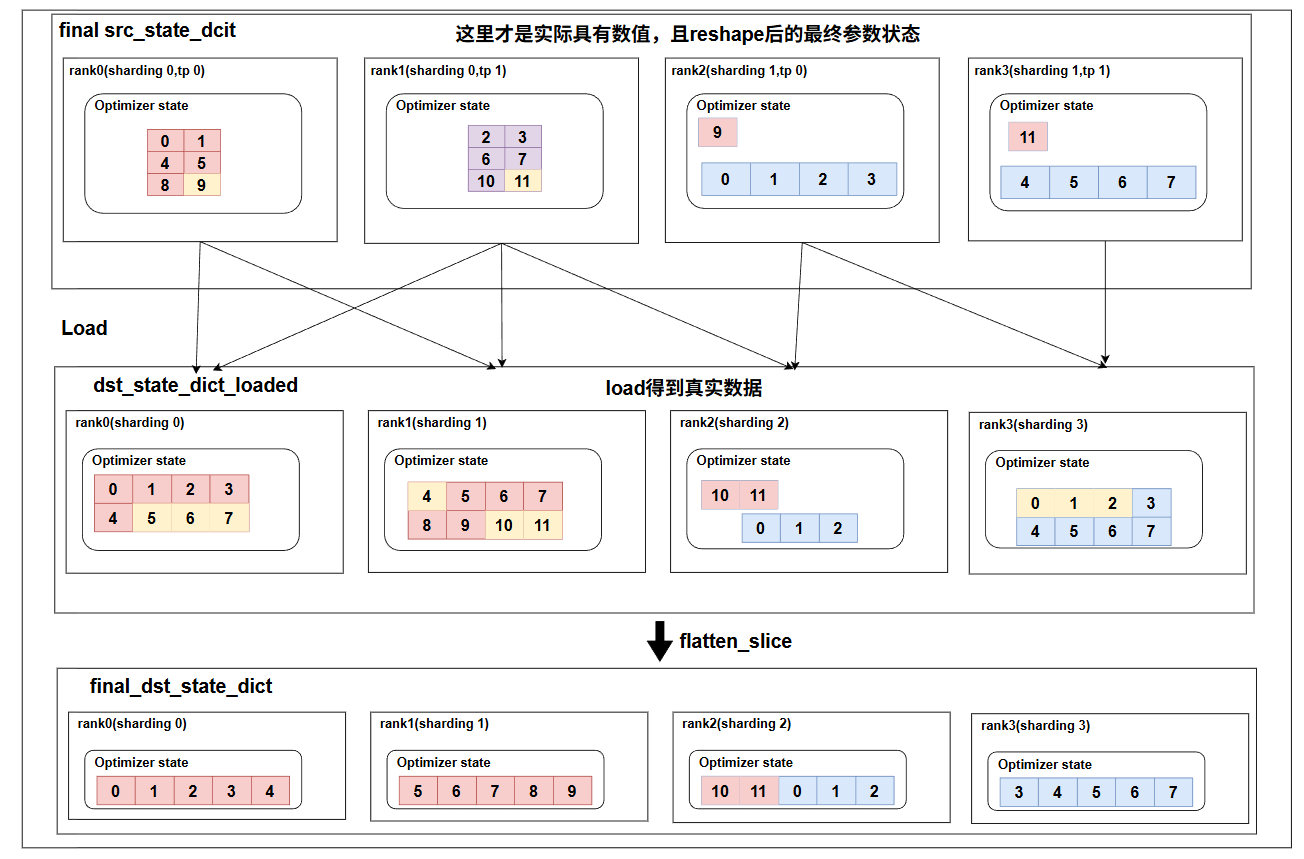
这里就是拿到最终的src的opt经过reshape后的数据,全部的数据都变成多维的了,此时dst也是多维的,调用load接口,即可正确加载参数,最后我们实际model此时需要的参数是flatten_range部分的参数,并且shape也是flatten的,所以要再flatten成一维。
6.2 Torch dcp错误示例
Save
load
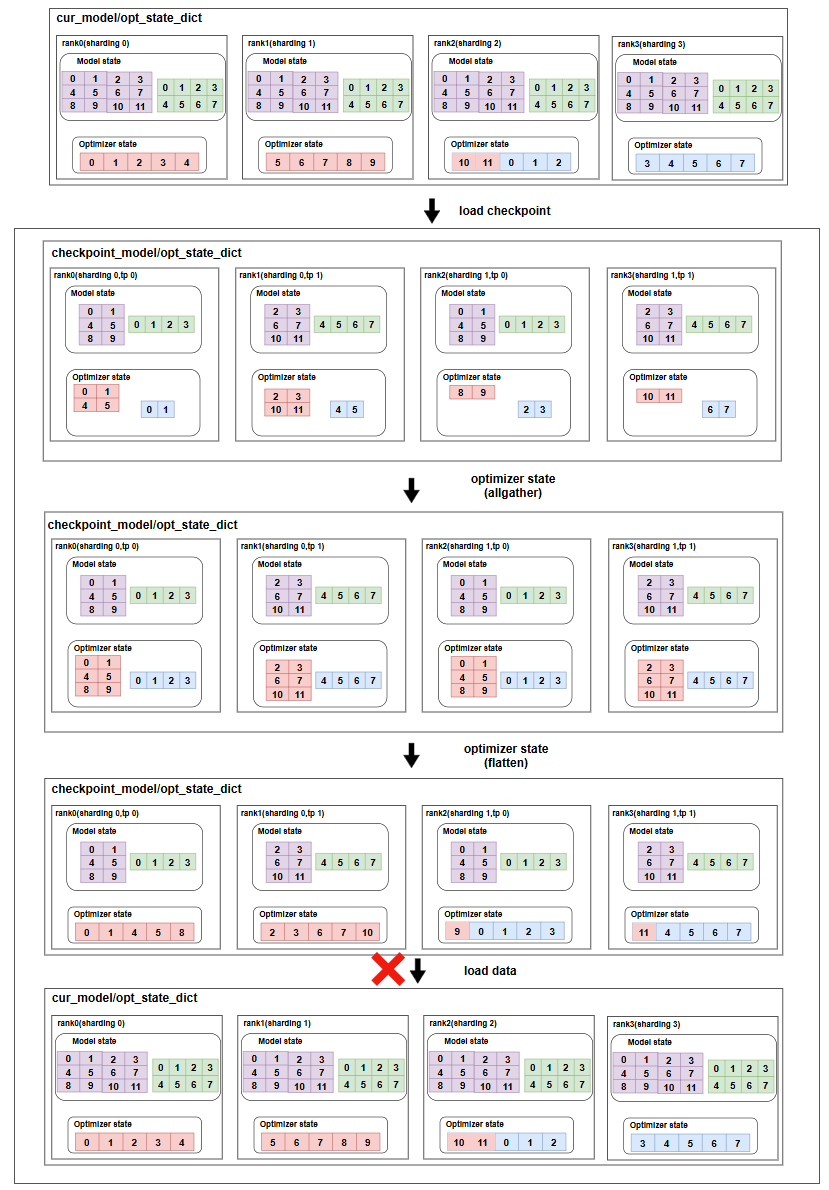
torch的DCP,在分布式训练时,只会把flatten的参数allgather回来,并做unflatten的,然后再按照sharding_groupsize,沿着第一个维度切块,即save的时候保留多维的tensor。而在load的时候,如果tp变成非tp,torch的DCP无法感知,此时加载的flatten的数据就是错误的。
4.AOAEngine
AOA(All-in-one-Arrow) 协议允许用户在单卡/全局视角下描述参数的转换操作,而不关心参数的具体切分方式
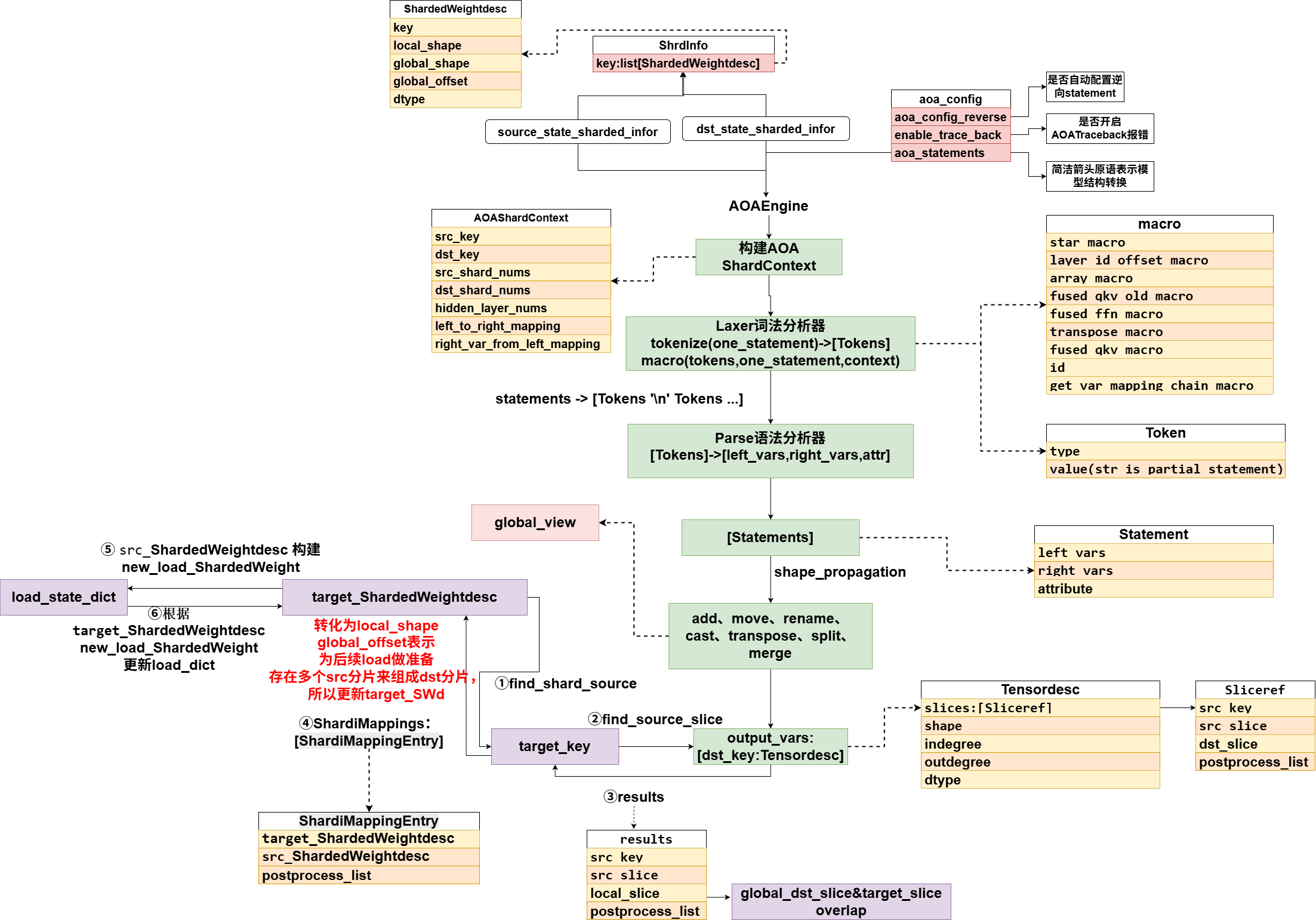
AOA的整理逻辑如上图所示,首先会收集checkpoint中的src和load_dict中dst的全局信息,整个AOA对模型结构转换的解析是在全局视角下去做的,首先通过src和dst中的全局信息构建全局上下文,然后用Laxer词法分析器,解析每一个aoa_statement,为token,并用macro进行处理,因为很多macro是token粒度的展开,所以解析为token更好操作(也为语法分析器分离左右操作数和属性做准备),并且每一句aoa_statement解析成[tokens]后,都会加一个换行符来识别每一个statement的转换,接着用Parse语法分析器,将每一句statement,当前是[tokens]列表,转换成left_vars,right_vars,以及attribute。即得到多个这样的statement,每个statement进行处理,这些statement仅仅可能是七中原语的操作,因此直接识别是哪种原语进行操作即可,全部处理完成后得到output_var,这是src到dst的全局映射,并且是用slices切片表示,然而我们需要src到本地target的映射,target即load_dict中的tensor,它不一定是全局大小,因此target slice需要和此时全局dst slice切片做overlap得到local_slice,同时再看src到overlap的映射,得到新的src切片到local_slice的映射,注意这时候src并不是checkpoint里面保存的切片,而是在以全局视角看checkpoint里面的参数进行切片得到的,那么我们要将其转换成local_shape和global_offset的表示方法即src_shardedWeightdesc,后续用于load_state_dict,并且我们是用src_shardedWeightdesc创建new_state_dict去load,因为必须要保持param name一样才能从ckpt中load数据,load下来之后,再赋值到target_shardedweightdesc指向的那片dst_tensor的数据。
注意一个重要的点,TensorDesc里面的dtype是为了记录src的dtype,并在后续和target的dtype进行比较,看是否在aoa statements中正确配置了cast,如果没配置会进行报错,而cast的操作,是记录在process_list里面进行传递的,后续统一load数据后,做cast,因为load数据的时候要跟checkpoint里面src的param dtype对齐,才能正确load,所以cast操作是需要被延迟操作的,包括transpose也是。
1.AOAShardInfoContext
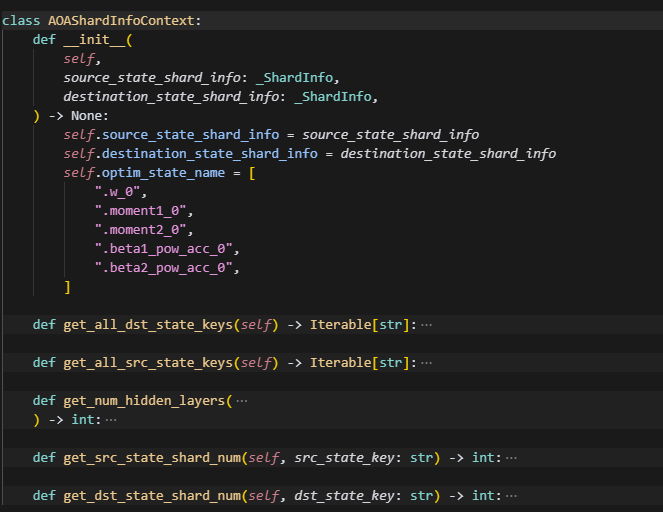
这个主要用于记录上下文信息,保留一些信息,给后续操作可调用。
source_state_shard_info和destination_state_shard_info分别表示需要load下来的ckpt对应策略的参数分片信息,和当前正在执行的策略的参数分片信息,格式为_ShardInfo = dict[str, list[ShardedWeightDesc]],即包含,同一个key,再不同rank上的参数分片状态(包括local_shape,global_shape,global_offset),如果是类似dp这样的,同一个key只会在单个distcp文件中保存,因此只有一个参数分片状态。
get_all_dst_state_keys与get_all_src_state_keys则是辅助函数获取其中所有的key,get_num_hidden_layers通过aoa_config中是否配置了$LAYER_ID,来正则匹配dst中所有key中的layer_id,例如下:
"ernie.layers.$LAYER_ID.self_attn.qkv_proj.weight -> ernie.layers.$LAYER_ID.self_attn.qkv_proj.weight, fused_qkv_old, num_heads=20, num_key_value_groups=5"
会以$LAYER_ID为分隔符,分成两份,然后中间以\d匹配,从而匹配到layer_id,遍历所有key,得到的做大ID+1,则为num_hidden_layer的层数。
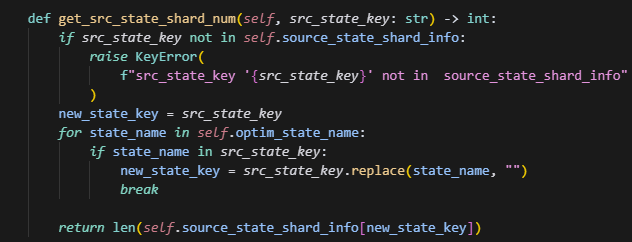
get_src_state_shard_num和get_dst_state_shard_num这两个主要是查看当前key对应参数的分片数,即tp数。
为什么要把optmizer的key也都转换成model的key来算呢,原因是,当做sharding的时候,opt的参数分片数=tp_nums*sharding_nums,直接求就有问题了。
2.Lexer(词法分析器)
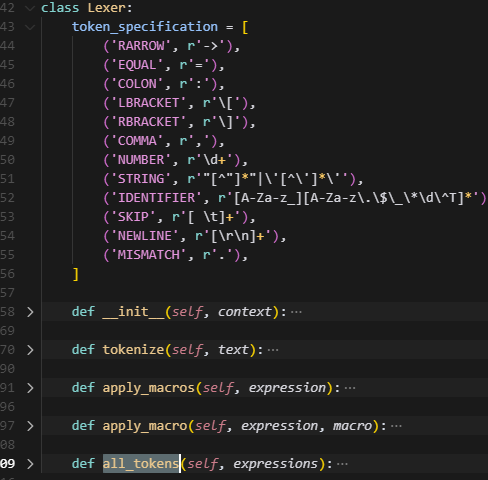
核心目标:为 AoA 表达式做词法分析(Lexing),并在词法分析前先应用已注册的宏展开,最终生成供解析器使用的 token 序列。
首先传入的参数expressions是aoa_conifg["aoa_statements"],这是一个字符串列表,形状如下:
aoa_config ='{
"aoa_statements": [
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0, fused_ffn"
]
}'
每一个expression会使用apply_macros,即对每个expression,遍历使用所有的已经注册好的macro。
在进入macro之前,会使用tokenize方法将expression解析成多个token,按照token_specification中的正则项进行匹配,name作为key,匹配到的实际内容作为value,比如上述的aoa_config的第一条,首先会根据identifier获取到第一个token:llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight,遇到空格会skip,然后根据rarrow匹配到->,紧接着再根据identifier获取到下一个token,知道最终结束,而每个text都会判断一下后面有没有\n,没有就补充,从而得到NEWLINE,标志着一条text匹配结束(必须注意,这里加\n,就可以在后续调用parser的时候,读取到这个换行符,结束当前这一行statement的解析)。
被所有macro处理后,会得到一个results列表,列表里面也都是expression样子的表达式,最终Lexer会把result_expression再次调用tokenized解析成token返回,给到parser里面做处�理。
3.Parser(语法分析器)
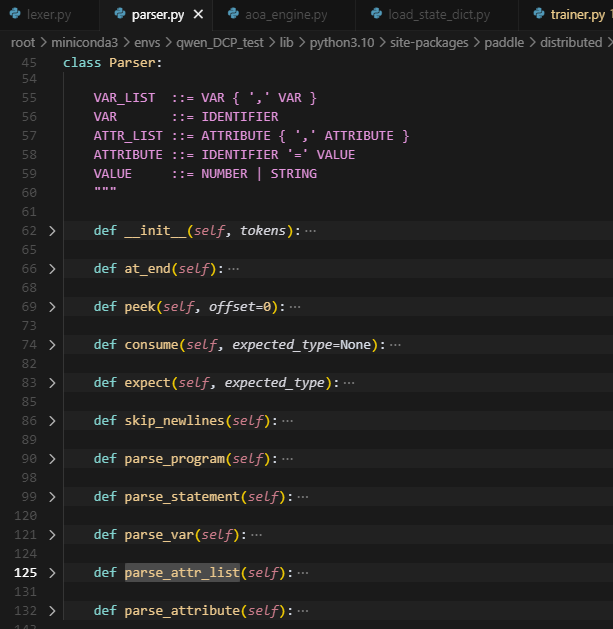
这个Parser解析器,主要是对macros处理后的statement(由macros处理后,新生成的aoa表示语句),并且被Lexer处理成一个token列表,针对这个token列表做分析,每个statement会被分成多个token,根据token_type,最终得到left_var,right_var,attribute。
主要调用函数就是parse_statement,根据IDENTIFIER(标识符)、COMMA(逗号)、RARROW(箭头)、EQUAL(等号)、NEWLINE(\n)、来区分,当前的token是属于left_var,right_var,attribute的哪一个。最终会返回一个List[Statement],包含每一个statement解析获得的Statement。
4.Macros
5.AOAEngine模块解析
所有模型结构相关的参数转换,都可以使⽤rename、merge、split、transpose、cast、remove和add这7种原语组合��出来。
下面按 7 种原语给出判定条件与规范格式(AOA 一条语句的通用形态是:左变量列表 -> 右变量列表[, 属性列表]):
- 重命名 rename
- 条件:左 1 个,右 1 个,且无属性
- 格式:`A -> B`
- 合并 merge(concat)
- 条件:左 多个,右 1 个,且属性仅有 `axis`,缺省axis=0
- 格式:`A, B, C -> OUT, axis=1`
- 切分 split(split)
- 条件:左 1 个,右 多个,且属性仅有 `axis`,缺省axis=0
- 格式:`IN -> A, B, C, axis=1`
- 置换 transpose(permute)
- 条件:左 1 个,右 1 个,属性含 `permute`
- 格式:`A -> B, permute=[2,0,1]`
- 特例:`permute=[]` 表示维度反转(代码里会按 ndim-1..0 生成,维度完全颠倒)
- 类型转换 cast
- 条件:左 1 个,右 1 个,属性含 `dtype`
- 格式:`A -> B, dtype='float16'`(字符串字面量外层引号会被去掉)
- 移除 remove
- 条件:左 1 个,右为下划线 `_`
- 格��式:`A -> _`
- 新增 add(占位声明输出名)
- 条件:左为下划线 `_`,右 1 个
- 格式:`_ -> B`
补充约束与细节:
- split/merge 必须且只能带一个 `axis` 属性,否则报错。
- 单输入单输出可同时带多个属性,但仅支持 `permute` 与 `dtype`(`axis` 会被忽略)。
- 属性间用逗号分隔;属性解析不跨行。
- 变量名 `_` 仅在 add/remove 中有特殊含义。
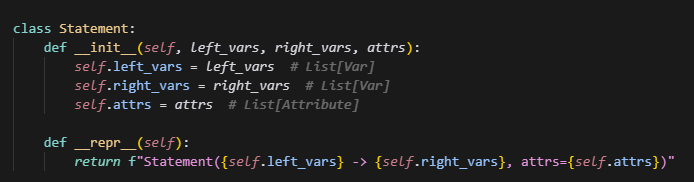
1.TensorDesc
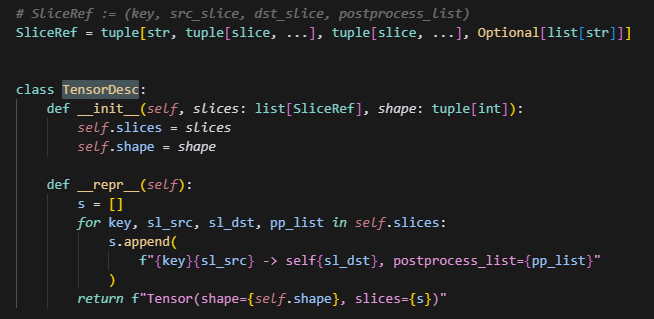
-
src_key: 源权重名(字符串)
-
sl_src: 源全局张量上的切片 tuple(每个维度一个 slice)
-
sl_dst: 目标张量上的切片 tuple(对应 sl_src 区间映射到目标的区间)
-
pp_list: 后处理列表(如转置 permute 列表字符串、dtype 标记),用于反向或正向应用
什么时候,slices会是一个列表呢?
比如,当要合并某个参数时,可能是将这个参数的多条slice合并成一个tensor,因此是一个列表。
2.find_shard_sources
s0 = ShardedWeightDesc(
key="s0",
local_shape=(2, 2),
global_shape=(2, 2),
global_offset=(0, 0),
)
s1 = ShardedWeightDesc(
key="s1",
local_shape=(2, 2),
global_shape=(2, 2),
global_offset=(0, 0),
)
d0 = ShardedWeightDesc(
key="d0",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
d1 = ShardedWeightDesc(
key="d1",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
self.source_state_shard_info = {
"s0": [s0],
"s1": [s1],
}
self.destination_state_shard_info = {
"d0": [d0],
"d1": [d1],
}
self.aoa_statements = [
"s0, s1 -> s, axis = 1 \n",
"s -> s, dtype = 'float64'\n",
"s^T -> d\n",
"d -> d0, d1, axis = 1",
]
###################################################################################
query = ShardedWeightDesc(
key="d1",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
# d1[0:2, :] <--- s0[1, :]^T
src_sharded_weight_desc0 = ShardedWeightDesc(
key="s0",
local_shape=(1, 2),
global_shape=(2, 2),
global_offset=(1, 0),
)
dst_sharded_weight_desc0 = ShardedWeightDesc(
key="d1",
local_shape=(2, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
# d1[2:4, :] <--- s1[1, :]^T
src_sharded_weight_desc1 = ShardedWeightDesc(
key="s1",
local_shape=(1, 2),
global_shape=(2, 2),
global_offset=(1, 0),
)
dst_sharded_weight_desc1 = ShardedWeightDesc(
key="d1",
local_shape=(2, 1),
global_shape=(4, 1),
global_offset=(2, 0),
)
shard_mapping_entry0 = ShardMappingEntry(
target_slice=dst_sharded_weight_desc0,
source_slice=src_sharded_weight_desc0,
postprocess_list=["float64", "[1, 0]"],
)
shard_mapping_entry1 = ShardMappingEntry(
target_slice=dst_sharded_weight_desc1,
source_slice=src_sharded_weight_desc1,
postprocess_list=["float64", "[1, 0]"],
)
answer = [shard_mapping_entry0, shard_mapping_entry1]
self.queries.append(query)
self.answers.append(answer)
idx=0;
query = self.queries[idx]
answer = self.answers[idx]
result = self.aoa_engine.find_shard_sources(query)
self.assertEqual(result, answer)
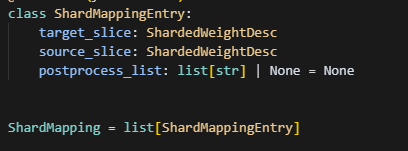
如上举个例子,find_shard_sources,得到的是,一个ShardMapping,ShardMapping = list[ShardMappingEntry],ShardMappingEntry保存了一个source_slice切片的�对应位置的数据,映射到target_slice切片的什么位置,以及映射过去要做什么操作,即postprocess_list,因此ShardMappingEntry包含三个参数。比如上面这个例子,上面展示了一个,从两个2*2的tensor,按axis=1维度拼接后,转置成4*2的矩阵,接着再转换dtype,同时按照axis=1切分,得到d1,d2。而此时,find_shard_sources(query),即将d1的切片信息输入,就可以获取到这个d1的数据,是由source的哪些切片数据获取的,可以用下图展示:
可以看到,find_shard_sources(D1)将得到两个ShardMappingEntry,一个是S0的第一行切片对应D1的前两行,另一个是S1的第二行切片对应D1的后两行,并且要做一个转置操作。
5.FlexCheckPoint示例分析(DCP+AOA)
1.tensor merge
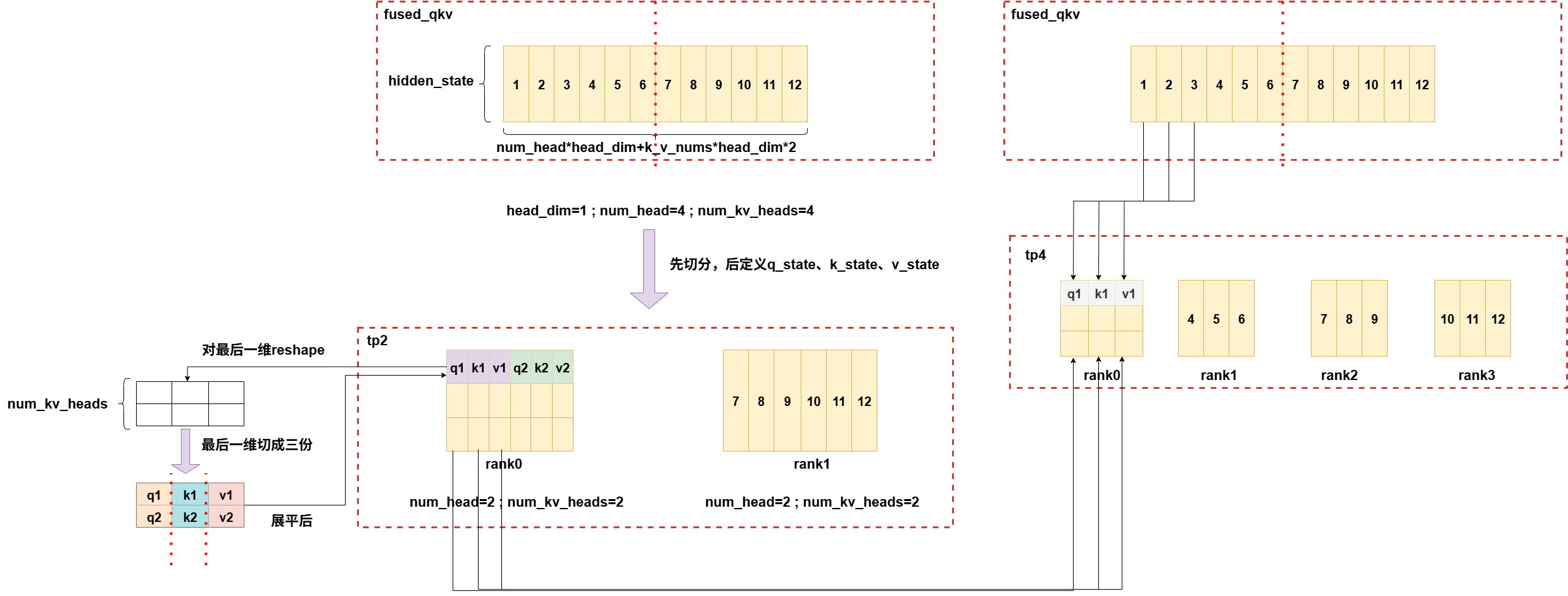
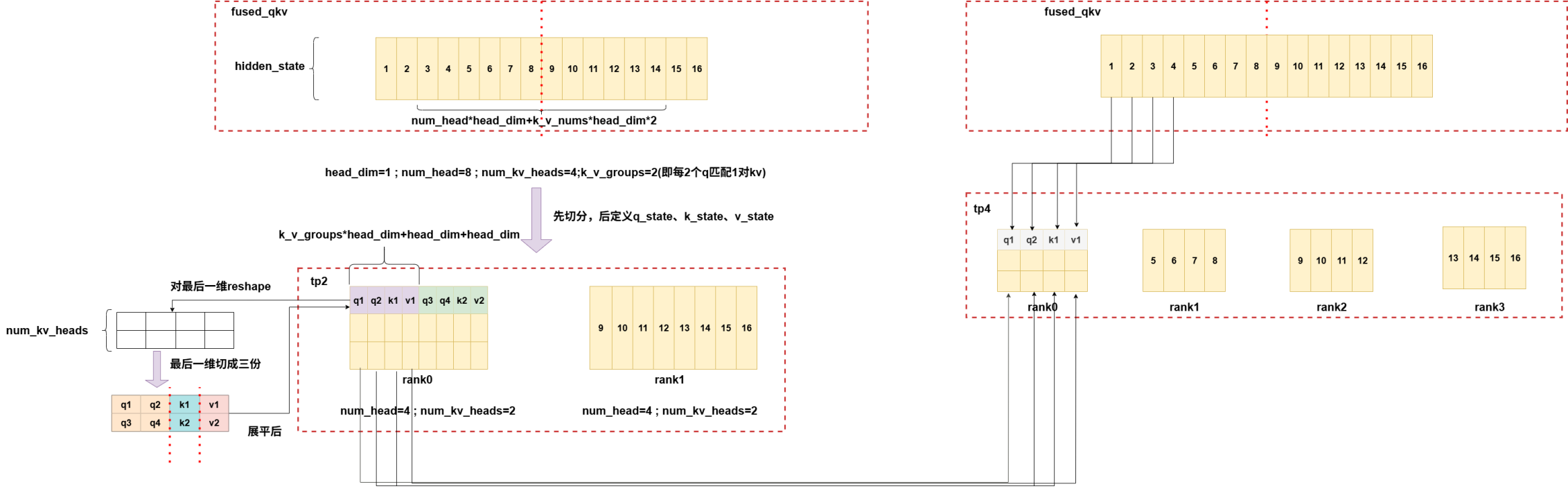
2.两种不同的fused_qkv
fused_qkv(llama)实现逻辑图:
tp2->tp4,num_heads=k_v_nums:
tp2->tp4,num_heads>k_v_nums:
old_fused_qkv(ernie)实现逻辑图:
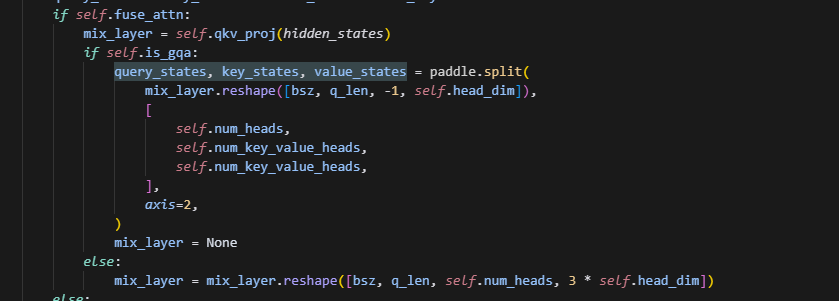
![]()
tp2->tp4,num_heads=k_v_nums: 此时逻辑同上,也是均分最后一维。
tp2->tp4,num_heads>k_v_nums:
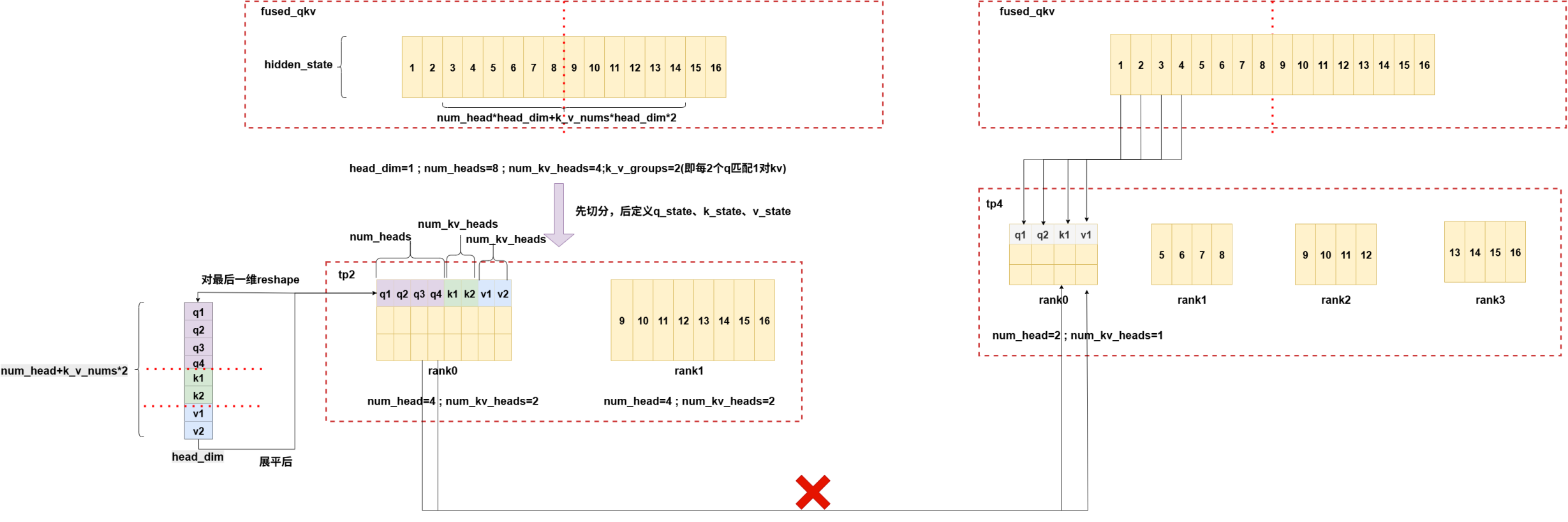
6.full param
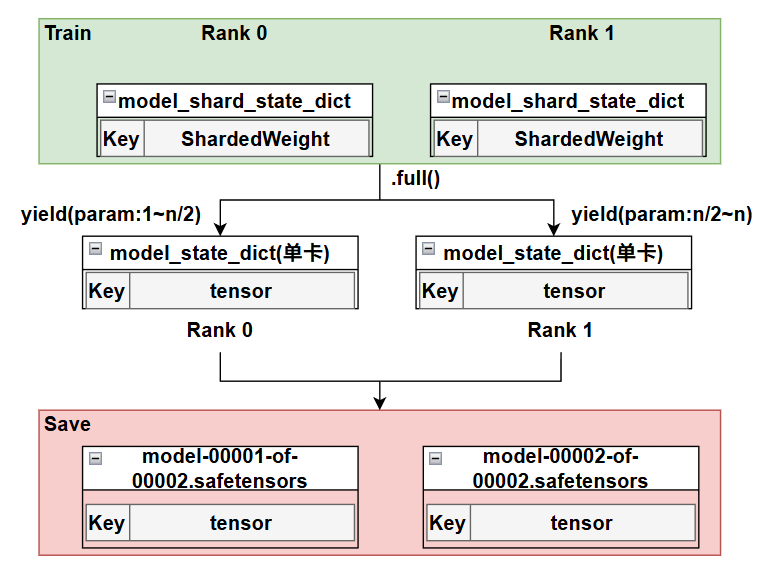
在开源上,我们通常训练完的文件保存的都是pdparam的格式,而huggingface上比较通用的都是safetensor的格式,每次都要case by case地去写转换脚本,把分布式训练的分片参数,转换成全量单卡视角的参数,再划分到多个safetensors文件里,非常耗时,而且脚本也比较依赖具体的模型和分布式训练方法,所以我们Flexcheckpoint最重要的一点之一,也是提供任意分布式训练的权重可以直接转换为safetensor格式保存,无需训练人员去case by case地写脚本。
同时和推理部门对接的时候,他们也希望得到一份全量的safetensor参数,可以直接在huggingface上下载的模型上跑,不需要知道我们训练这边用的什么策略做训练的,不然还要去调整组网的结构,很低效。
因此在原来的AOAEngine基础上我们开发了full param的接口,在训练完成后,可以直接调用full接口(这个full方法直接写在了Layer方法里,所以model天然继承,可以直接调用),采用full param的一套逻辑来做转换。
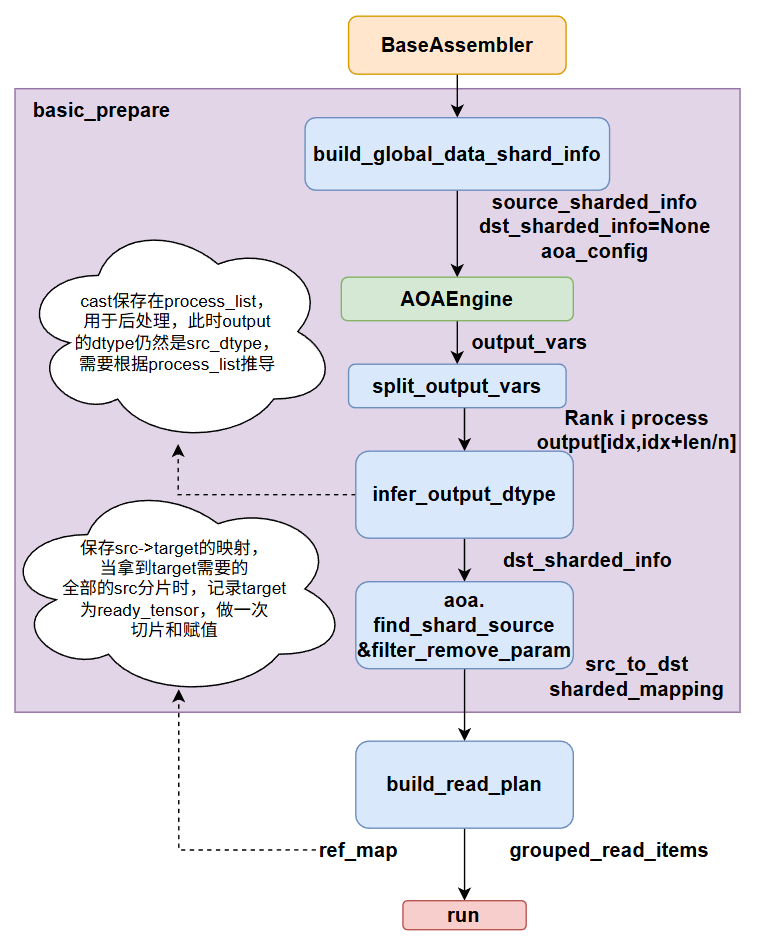
如图是一个full param的基类,整个流程是获取当前的source_sharded_info,和aoa_config,dst_sharded_info此时为None,因为我们当前是没有组网的,当前的组网是正在训练的这个model,而这个model是基于分布式策略训练的,所以我们没有单卡视角下的组网,因此dst_sharded_info此时为None,我们在AOAEngine中做了dst_sharded_info=None的适配,同时加了一个有向图的逻辑来区分中间变量和我们要转换的目标变量——**这里要解释一下,主要是如果我们没有要转换的目标组网的信息,我们无法知道aoa_statement里面配置的哪些右边的key,是新的key,或者是中间变量,比如paddle和huggingface的很多model layer的命名是有区别的,所以需要配置aoa_statement做rename,这时候我们就必须要区分中间变量和最终的target变量,因此就用入度和出度来区分。**这里通过获取output_vars我们就可以得到全部的target key以及它的全局状态信息,但是这时候只有param信息,没有实际的数值,我们需要从当前训练完成的model的param里面去load得到,因此我们先获取当前rank需要处理的output,这里我们设计的分片存储,所以处理target param也是每个rank处理一部分,并且是yield,有三点好处:①处理完一个param可以立即获取②处理的param数量可控,可设置数量随意调试③可以及时清理已经使用过的param数据,释放显存。**这里还有一点需要注意,cast和transpose都必须在load数据后才能执行,因为在load数据时,全局维度大小和dtype必须保持一致才能正常load下来,在赋值给target param的时候再去做后处理,即cast和transpose。所以这里我们从aoa拿到的仍然是source_state_dict的param的dtype,需要做一个dtype的推理,即可构建好我们的destination_sharded_info,在无组网的情况下,它也是最终的target param的infomation。**我们调用find_shard_source即可找到source param到destination param的切片映射,并过滤掉remove的param,即原来的model有,而准备保存的checkpoint想将其去掉的那些param。最后通过build_read_plan建立ReadItem,这里建立的ReadItem和load state dict过程的ReadItem不太一样,这里发送的大小和接收的大小直接用的src tensor的带大小,其实已经有了mapping,这里是可以像load state dict那样做一个优化的,只发送和接收overlap的部分即可。下面给出了两种不同Group的实现实例,是分别继承基类BaseAssembler设计的,SingleCommGroupFullParamAssmber主要是在单个group时使用,而HVCommGroupFullParamAssembler把通信组分成水平通信组和垂直通信组,通常在混合并行,如dp+tp,tp+pp等场景使用。
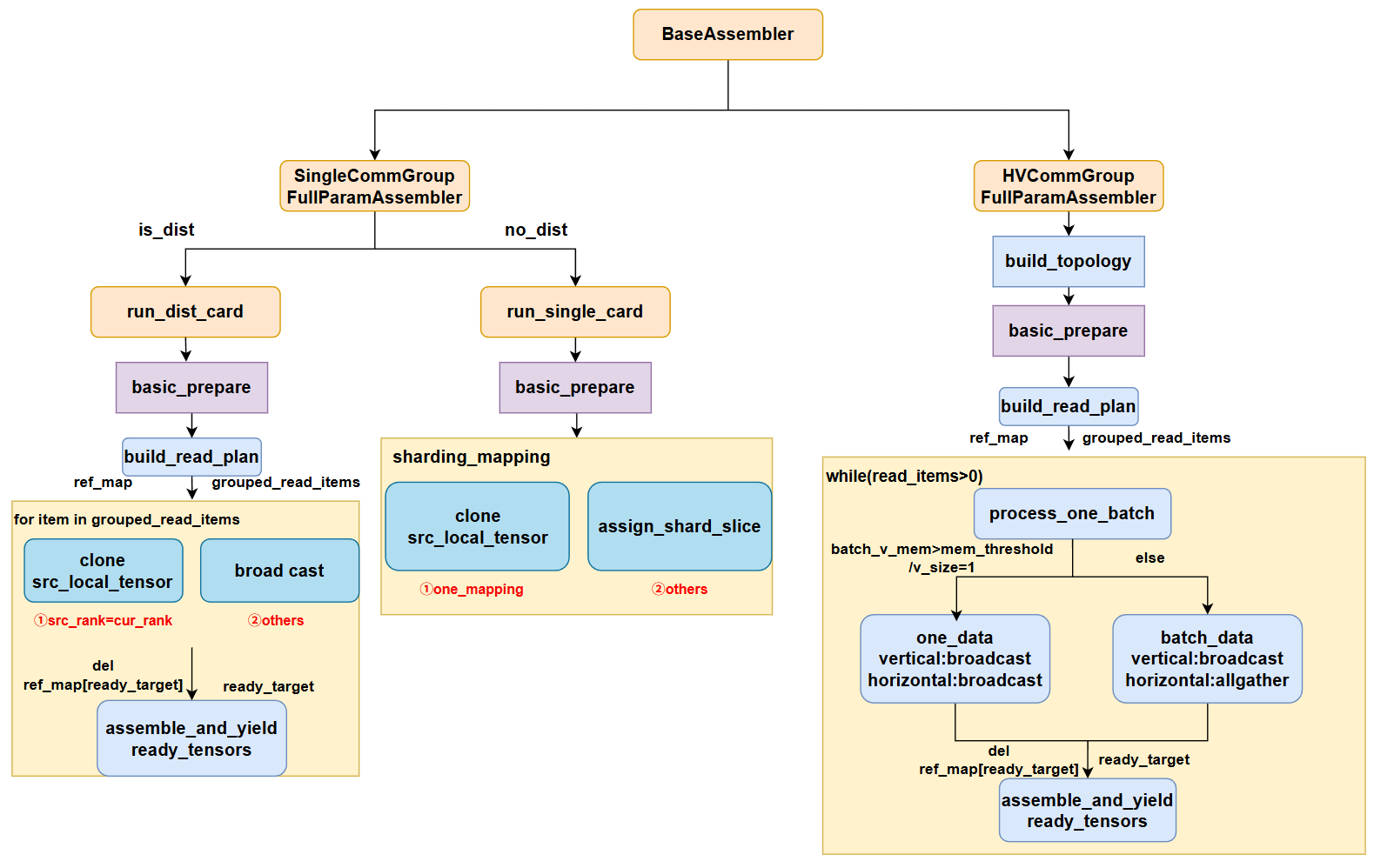
首先SingleCommGroupFullParamAssmber,分为dsit和非dist,如果本身就是单卡执行,则如果是one_mapping,说明是一对一param的转换,则直接clone现有的src_local_tesor就可以,否则说明是多对一或者一对多转换,这时候就要调用assign_shard_slice进行src和dst分片的切分,切分出overlap的那部分,然后赋值,从而得到最终的target param。如果目前在做并行,那么如果src_tensor就在本rank上,则直接clone,否则就用broad cast 让其它rank都接收到这份参数。最后用assemble_and_yield_ready_tensors函数进行切片和赋值。
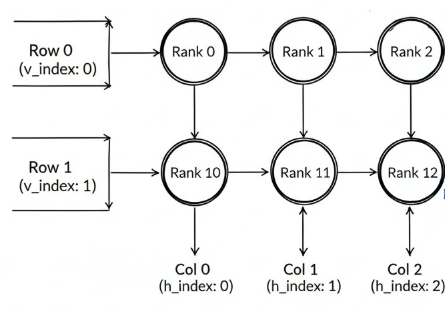
HVCommGroupFullParamAssembler主要是优化了混合并行场景下的full param,通过让垂直方向的每个group组内做broadcast,分别发送一个src_tensor,再在水平方向做allgather,共享每个垂直方向的数据,即可一次得到一个batch的src_tensor,相比于singlegroup的效率要高很多,并且在批量通信的同时,还可以去做tensor的切分和赋值操作,做到计算和通信overlap,当然这里可能overlap提升性能并不大。如果vertical方向只有一个,就退化到singlegroup的通信,或者此时一组vertical的通信量会大于设定的阈值,目前设置的8G,则也会退化到单个src_tensor做broadcast。如下展示了HV两个方向时的分组状况。
def _assemble_and_yield_ready_tensors(
self, ready_tensor_names: list[str]
) -> Iterable[tuple[str, paddle.Tensor]]:
"""
Assembles, yields, and cleans up tensors whose dependencies are all met.
This logic is shared across different communication strategies.
"""
if not ready_tensor_names:
return
for name in ready_tensor_names:
target_desc = self.destination_sharded_weight_desc[name]
local_tensor = paddle.empty(
target_desc.local_shape, dtype=target_desc.dtype
)
cur_sharded_tensor = ShardedWeight(
key=target_desc.key,
local_tensor=local_tensor,
local_shape=target_desc.local_shape,
global_shape=target_desc.global_shape,
global_offset=target_desc.global_offset,
)
for mapping in self.destination_sharded_mappings[name]:
src_desc = mapping.source_slice
dst_desc = mapping.target_slice
src_shard_template = ShardedWeight(
key=src_desc.key,
local_tensor=paddle.zeros(
src_desc.local_shape, dtype=src_desc.dtype
),
local_shape=src_desc.local_shape,
global_shape=src_desc.global_shape,
global_offset=src_desc.global_offset,
)
received_shards = []
for desc, tensor in self.sharded_desc_to_tensor.items():
if desc.key == src_desc.key:
received_shards.append(
ShardedWeight(
key=desc.key,
local_tensor=tensor,
local_shape=desc.local_shape,
global_shape=desc.global_shape,
global_offset=desc.global_offset,
)
)
# received_shards 是经过broad cast后得到的dst需要的全部分片 ,而src_shard_template是我们需要的src参数,用来给dst_tensor赋值
recover_shard_tensor_from_shards(
received_shards, src_shard_template
)
assign_sharded_slice(
src_desc=src_desc,
src_shard=src_shard_template,
dst_desc=dst_desc,
dst_shard=cur_sharded_tensor,
postprocess_list=mapping.postprocess_list,
)
src_shard_template.local_tensor._clear()
yield name, cur_sharded_tensor.local_tensor
need_clear_source_names = self._update_consumer_counts(
ready_tensor_names
)
self._cleanup_consumed_shards(need_clear_source_names)
这个函数有一点需要注意,src_desc记录的信息,是当前dst_desc实际需要的那部分数据的信息,而received_shards是经过broad cast得到dst需要的全部分片,这些分片并没有跟dst做overlap,所以拼接起来的范围和dst的范围是大于等于的关系,所以我们要用src_desc构建一个src_shard的模板,和所有received_shards计算重叠部分,从而用实际数据填充src_shard_template,最后再用src_shard_template填充dst_tensor。
7.和其它CheckPoint对比
7.1 UCP(universal checkpoint)
UCP的介绍
UCP(Universal Check Point) ,由deepspeed提出的ckpt方法,配合Deepspeed Checkpoint使用,其核心思想是,save的时候,按照分布式分片方式存储,因此save不会消耗多余的时间,并且保存对应的全局metadata信息,再离线转换(当然如果没有发生分布式变化,则可以不转换),离线转换,存储为Universal Checkpoint,论文也叫atomic checkpoint。这些checkpoint即根据分片参数和meta信息,转换成完整的参数,在cpu上转换,并且是逐参数并行转换,转换完立即释放空间,全部转换完成后,load时,target 参数,再从这个全局参数Universal Checkpoint中读取参数,即从分片->全局->分片,核心框架如下图所示。
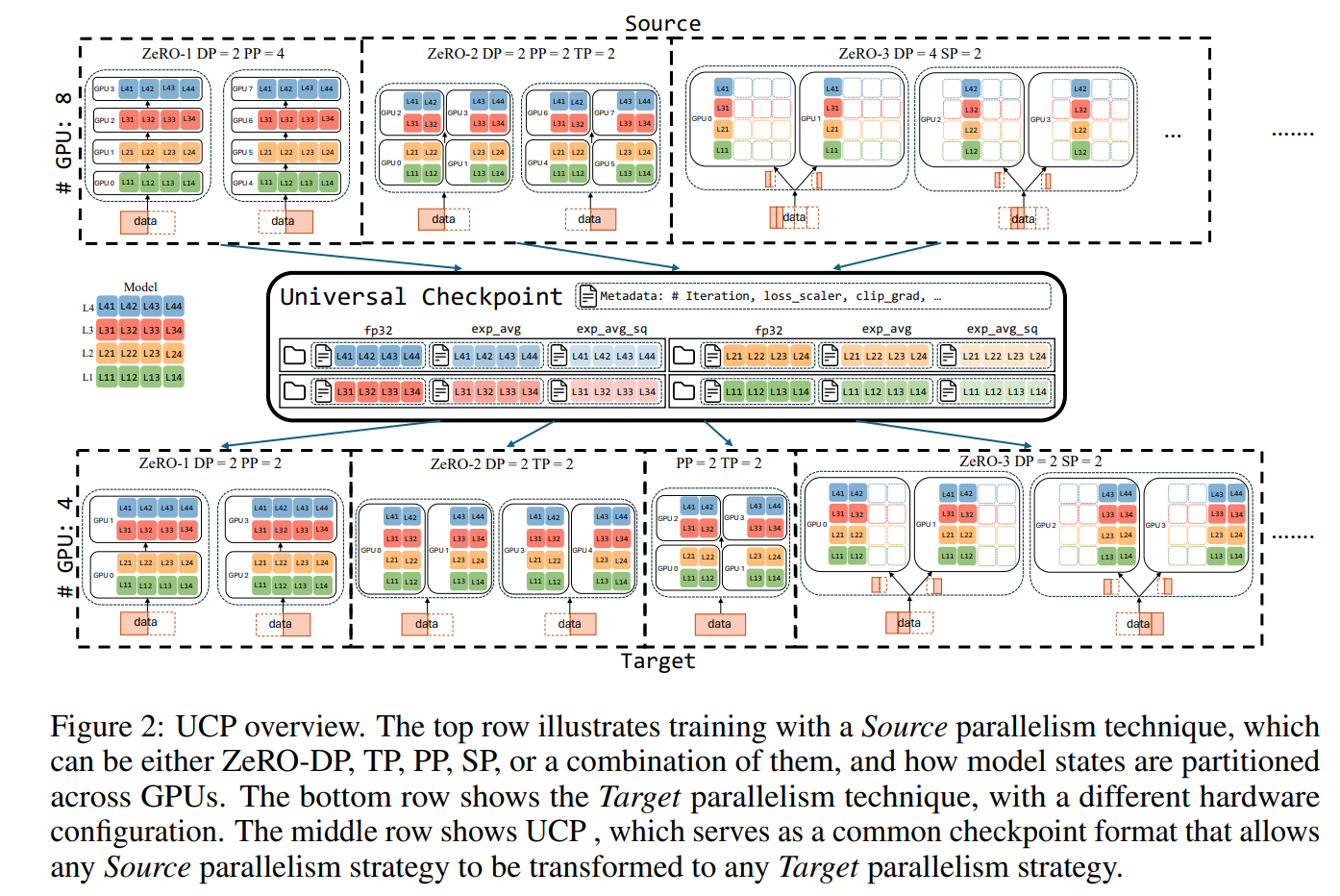
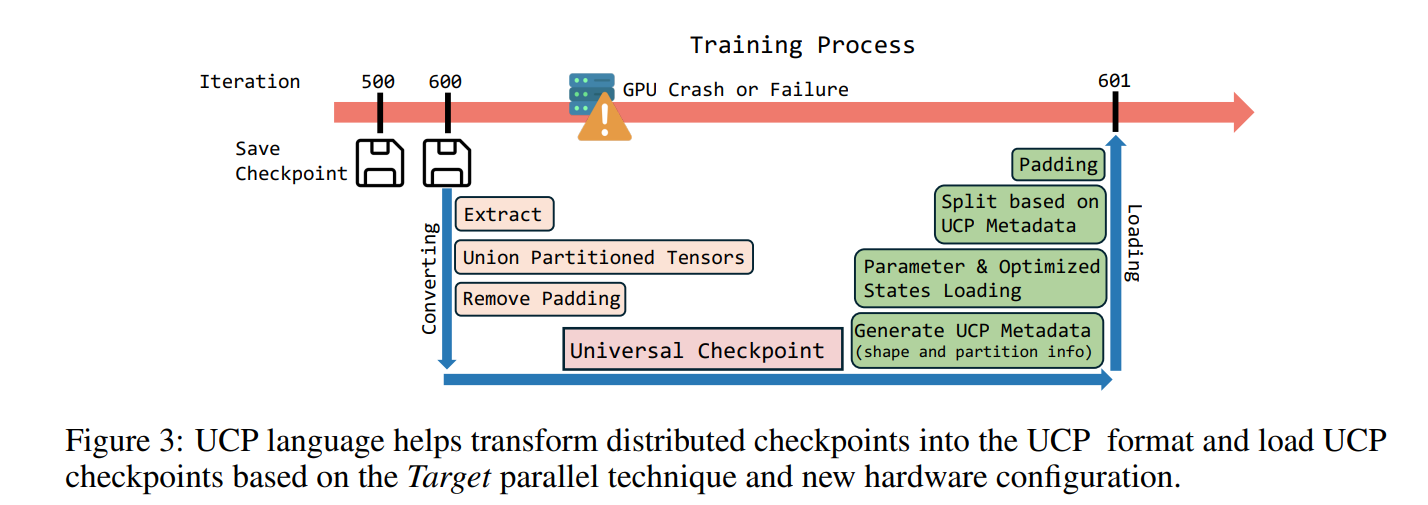
UCP的核心原语如下,Extract,Union,StripPadding。主要是提取参数列表,把分片参数给整合成全局完整参数,并且将padding部分给去掉,因为load时只需要实际数值部分。如下图展示了一个在第600次迭代断开,接着在601次迭代接续训练的过程。
如下展示了Zero-3的param 从dp4到dp2的转换,即从distributed checkpoint里面提取每个分片参数,然后用union,将分片参数合并,再将padding数据去除,save成universal checkpoint。load的时候,逐参数load,并根据当前target的并行度,来划分参数。
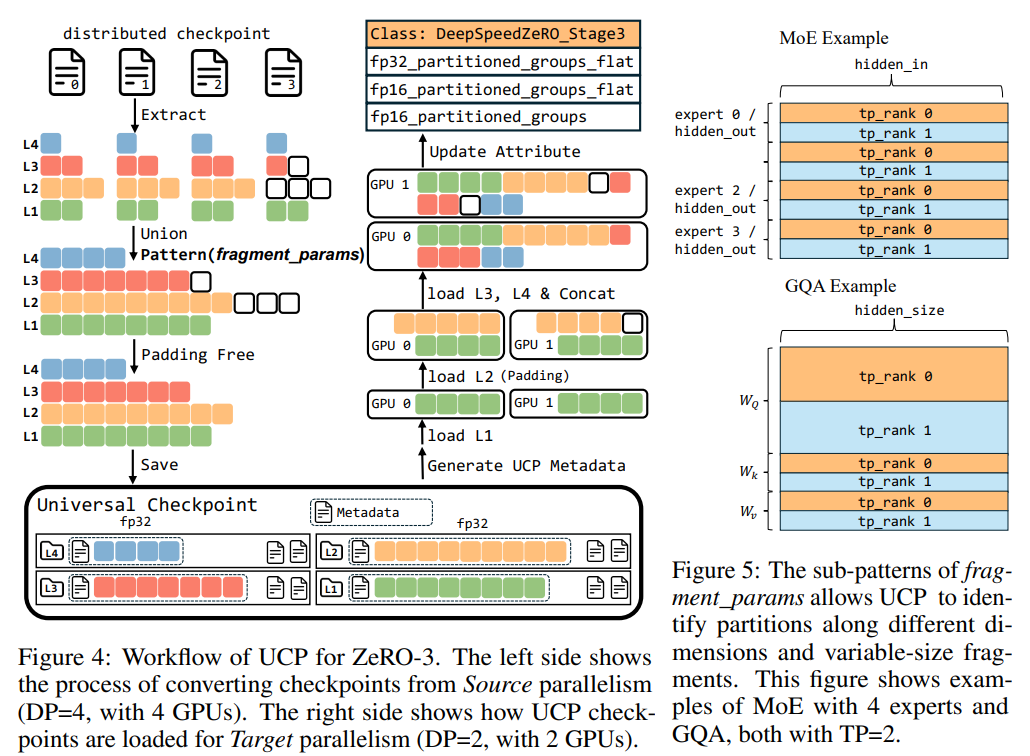
UCP与FC中的DCP对比
因为FC的DCP即参考了torch 那一套DCP的实现方式,因此这里直接对比UCP与DCP的差异:
| UCP (DeepSpeed) | DTensor/DCP (PyTorch) | |
|---|---|---|
| 中间表示 | 完整参数(每个参数一个合并后的多维 tensor 文件) | 无中间表示,保持分片格式 + 丰富的元数据 |
| 转换策略 | Source分片 → 完整参数 → Target分片(两步解耦) | Source分片 → Target分片(直接映射) |
| 核心抽象 | "原子 checkpoint"(每参数的完整 tensor + 元数据) | DTensor 的 placement 描述(Shard/Replicate + DeviceMesh) |
✅ UCP 的优势
| 优势 | 说明 |
|---|---|
| 实现极其简洁 | Save → Full 和 Full → Load 各自独立,代码量小、逻辑清晰,正确性容易验证 |
| 对训练框架零侵入 | Save 端完全不改(各 rank 原生存 shard),只需额外跑一个离线脚本;Load 端给参数挂一个方法即可 |
| Source 和 Target 完全解耦 | 新增一种并行策略只需写"该策略 → Full"的转换器,不影响 Load 端 |
| 兼容历史 checkpoint | 只要有分布式 checkpoint 文件 + param_slice_mappings 等元数据,就能转换,不要求训练时用特定 tensor 类型 |
| 正确性保证强 | 中间有一个"完整参数"的物理文件可以人工检查/对比,debug 非常方便 |
| 支持 ZeRO 全系列 | 原生支持 ZeRO-1/2/3 的 flatten + 分片格式,以及 TP/PP/SP/MoE |
✅ DTensor/DCP 的优势
| 优势 | 说明 |
|---|---|
| 无需合并完整参数 | 永远不需要在内存或磁盘上产生单个参数的完整副本 |
| 单参数超大时更友好 | 对于几十 GB 级别的单个参数(如超大 embedding),不需要任何节点能放下完整参数 |
| 没有离线转换步骤 | Save 和 Load 一步到位,不需要用户手动跑转换脚本 |
| 磁盘零额外开销 | 不产生 UCP 那样的完整参数副本,只存分片 + metadata |
| 在线 resharding | Load 时直接按需从源分片读取目标需要的部分(支持 partial/lazy read) |
| 与 PyTorch 生态深度集成 | DTensor 是 PyTorch 原生类型,FSDP2、TP 都基于它,DCP 与之无缝配合 |
| 弹性训练更自然 | 加减节点时无需离线步骤,load 时自动 reshard |
❌ UCP 的缺点
| 缺点 | 说明 |
|---|---|
| 需要离线转换步骤 | 用户必须手动跑 ds_to_universal.py,跨策略恢复的流程不够自动化 |
| 额外磁盘空间 | 完整参数副本约等于模型大小(FP32 权重 + 优化器状态),大模型可能多占数百 GB |
| 离线转换有时间开销 | 虽然不阻塞训练,但大模型的转换可能需要几十分钟到数小时 |
| 加载时单参数内存峰值 | 加载每个参数时需要完整加载到 CPU 内存再切片,超大单参数可能有压力 |
| 依赖 DeepSpeed 生态 | 紧耦合于 DeepSpeed 的 ZeRO/TP/PP 实现,难以用于纯 PyTorch FSDP 等其他框架 |
❌ DTensor/DCP 的缺点
| 缺点 | 说明 |
|---|---|
| 实现复杂度高 | 需要在存储层面处理多维 stride 映射、跨文件 partial read、各种 placement 组合 |
| 对训练框架有要求 | 要求模型参数用 DTensor / ShardedTensor 封装,不能直接用于任意框架的裸 torch.Tensor |
| 不兼容 ZeRO 的 flatten | ZeRO 把多个参数拼成一个大 flat tensor 的方式与 DTensor 的"每个参数独立描述 placement"理念冲突,支持困难 |
| Debug 困难 | 没有一个"完整参数"的中间产物可以检查,resharding 出错时定位问题较难 |
| TP resharding 仍有复杂度 | 当 TP 维度变化时(行并行/列并行/sub_params),resharding plan 的计算依然复杂 |
| 生态成熟度 | 相比 UCP 已在 BLOOM-176B 等真实超大模型上验证,DCP 的跨策略 resharding 仍在快速演进中 |
适用场景对比
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| DeepSpeed ZeRO + Megatron 风格训练 | UCP | 原生支持,久经验证 |
| PyTorch FSDP2 + TP 训练 | DCP | 原生 DTensor 生态,无缝集成 |
| 超大模型(单参数 > 单机内存) | DCP | 不需要合并完整参数 |
| 偶尔切换并行策略(低频操作) | UCP | 离线转换一次即可,简单可靠 |
| 频繁弹性扩缩容 | DCP | 在线 reshard,无需手动转换 |
| 跨框架迁移 checkpoint | UCP | 完整参数是最通用的交换格式 |
| 需要快速 debug checkpoint 正确性 | UCP | 中间有完整参数文件可直接检查 |
7.2 Byte Checkpoint
与UCP关注灵活转换并行策略不同,它主要是关注写入速度。因为通常的训练在保存checkpoint的时候,会阻塞训练,而实际上,checkpoint的写入和下一轮的训练是一个可以并行。
解决方案:
1.异步持久化:利用Pinned Memory作为中转,GPU可以快速拷贝到CPU内存并立即恢复训练,后续写入由CPU线程负责写入存储。
2.分层存储:数据平面(Tensor Data) 直接写入高性能DFS,而控制平面(Metadata)则写入高可用数据库。